(2016年4月13日更新) [ 日本語 | English ]
HOME > 講義・実習・演習一覧 / 研究概要 > 小辞典 > 情報科学 > 計算機科学
文字とテキスト形式文字は、個々の文字をビット(b)列対応づけし(2元)符号化する。文字を表すビット列(2進数)とみなした時の数値を文字コード、この対応関係をコード系 character encoding system と呼ぶ。コード系は、1文字8ビットと16bがある。8bは最大28 = 256 文字しか表せず、漢字は16bコード系だけとなる。コンピュータ通信時のコード系不一致は、文字化け原因となり、情報交換を国際間で進めるために標準コード系が規格された。文字数字符号化方法を知ることは、ネットワーク社会の諸問題を知るため重要である。過去、機能の異なるPCやWS商品群が独立文化圏を形成しため、漢字は国内でも複数規格存在した。異なる文字コードを使うコンピュータ間では、通信時に規格間での文字コード変換が必要である。もう1つの規格化問題は、多数の言語圏が独自文字文化を持つことである。PC能力が向上し、これに関して統一規格検討中だが、文化の根幹に関わり難しい問題があるコード系: 選んだ記号(文字と記号)にビット列対応づけ符号化された関係 → コード表: コード系を示した表 文字コード(符号系)の種類EBCDIC (Extended BCD Interchange Code = 拡張BCD交換符号): 64年IBM発表 → 7b列記号割当BCD (binary coded decimals = 2進符号化10進数字, or BDIC)は4b列で"0-9"数字表現のみに作られ、数表現規約であった。EBCDICは、ビット列長を倍にし大小アルファベット、区切記号、制御命令を追加した。EBCDICはIBMコンピュータ(互換)OS標準とし85年頃まで使用したが、アルファベット符号が飛びABC順情報処理が難しかった。カタカナ追加EBCDIKも使われたが、カタカナ追加時に小文字符号をずらし(厳密なEBCDIKは小文字に符号を与えない)、海外交信困難であった。更に、OSにより小文字符号割り振りが異なり、メーカ間コンピュータでも文章が狂い複号(符号から元情報を復元すること)された。読み間違いは、目で気づきにくく大問題であった ISO規格 (international organization for standard) コード系国際的標準規格に、ISO/ITU-TのIS646(7単位符号)がある。これに準拠し、米国通商産業省文字規格でPCで主に使われるASCII(American Standard Code for Information Interchage)、日本通産省定めるJIS X0208がある。ASCIIは8ビット単位、JIS X0208は16ビット単位コード系である 日本ではJIS C6220「情報交換用符号」が規格制定され、これには「ローマ文字用7単位符号/片仮名用7単位符号」、「ローマ文字と片仮名用7単位符号/ローマ文字と片仮名用8単位符号」がそれぞれ含まれる 漢字2元符号化標準規格にJIS C6226「情報交換用漢字符号」(1978年制定)があり、非漢字(?や+等の記号群)453文字、JIS第1水準(高使用頻度漢字群)2965文字が指定され、普通の文章を書くには、さほど不便はない。しかし、人名地名等が足りず、3384(3388)文字追加し、追加漢字をJIS第2水準漢字(低使用頻度漢字群)といい、合計6802(6806)文字になった。これだけの文字を割り当てるため2進数16桁(16b = 2バイト)を用い、漢字文化圏を2バイト文化圏と呼んだりする。JIS C6226は,1983年に名称をX0208に変更し改訂が続き、JIS X0208:1997になった。1990年にJIS X0212「補助漢字文字セット」が追加された。これは印刷業界からの要望で、X0208漢字だけでは足りないため6067の漢字と非漢字を追加した規格である ISO-2022: 「世界中文字コード混在可能規格」 → ASCII文字と日本語漢字とを1ファイルで混ぜて使える 標準化組識国際的標準化組識国際標準化機構ISO, International Organization for Standard: 工業・科学技術全般に関する国際規格国際電気標準会議IEC, International Electrotechnical Commission: 電気・電子技術分野の標準化 |
電気通信標準化部門ITU-T (旧CCITT): モデムやFAX等の通信機器等の規格決定 MSAF, multimedia services affiliate forum: 世界10カ国通信事業者ソフト/ハードメーカー11社共同設立した統一ネットワークサービス提供団体。サービス技術をLotusのNPNや、NovellのNCSに統一する NIC, Network Information Center: ネット接続IPアドレス、DOMAIN名配布組織。JPNIC(日), InterNIC(米) IAB, Internet Archtecture Board: InternetとTCP/IPに関する標準化。IETFの上部組織IETF, Internet Engineering Task Form: Internetで扱う仕様の標準化組織 IETF策定仕様はRFC ####としまとめられ、上部機関のIABにより標準化の可否が決定される DAVIC, Digital Audio-Visual Interface Council: 双方向CATV技術仕様決定業界団体Cable ModemやVOD等の仕様検討・決定 OSF, Open Software Foundation: UNIX関連技術の普及団体W³C, World Wide Web Consortium: W³関連技術標準化団体 HTML標準仕様等策定 合州国標準化組識規格協会ANSI, American National Standards Institute: 規格統一標準化目的民間団体電気電子工学学会IEEE, Institute of Electrical and Electronics Engineer: コンピュータ科学(s.l.)発展目的 電子工業会EIA, Electronical Institute Association: 電子機器製造会社で構成される貿易通称団体 環境保護局EPA, Environmental Protection Agency Energy Star: EPA策定PC・周辺機器消費電力低減規格。米政府納入PCは規格準拠義務なため、殆どのPCやディスプレイがこの規格対応 NIST, National Institute of Standards Technology: 標準化団体。前身NBS (National Bureau of Standards)OMG, Object Management Group: オブジェクト指向の標準化団体。CORBAやIIOP等の標準化を行った VESA, video electronics standard association: 映像機器関連標準化団体 日本標準化組識日本工業標準調査会 JISC, Japan Industial Standards Committee: 通産省管轄組識で日本工業規格JIS制定情報処理学会IPS: 情報処理専門用語、情報処理コード・言語・データ通信等標準化を検討、JIS原案作成 日本電子工業振興協会(電子協) JEIDA, Japan Electronic Industry Development Association: 通産省関連 MT, OCR, MICR等のJIS原案作成。PCカード(PC等に指すカード型拡張機器)規格を指すことが多い 社団法人日本電子機械工業会 EIAJ, Electronic Industries Association of Japan |
ASCIIコード(ISO/ITU-T7ビットASCII)符号化アルファベット使用「ローマ文字」コード系は、全コンピュータがASCII規格に従うため文字コードを殆ど意識しない。ASCIIコードは、アルファベット・数字・記号に32-126の文字コードを割り振りる。コンピュータ内部では、その番号を2進数表記したのと同じビット列が個々の文字を表す(表2.10)。「列C」と「行R」の記号は16進法表示ビットパターンを示す。Aは16進法で41、2進法で1000001というビットパターンである。SPは空白spaceを、空欄は対応記号不要な未使用領域である。0-1列のNUL, CR、F行7列目のDELは、文字ではなくコンピュータに特定機能を実行させる役割が割り当てられる(機能コード)。Ex. CRに対応する16進法の0D、つまり2進法の1001101は、「改行」命令である。機能コードは、コード系の切り替わる所を示す制御文字列としても利用される7ビットASCIIは仏・独語アルファベットを扱えず1b加え256種記号表現する8ビット拡張ASCIIも使われる。8ビットを使うと情報操作時の信頼性が上がる バイト byte: コンピュータ情報表現ビット数は8の倍数を多様するのは8ビット単位でデータ処理し易いことに関係し、8ビットを1バイト(B)と呼ぶ。32bは4B、64bは8Bで、2進数8桁分が1Bである 1英文字表現単位にバイト(B)を作った。データをbやB単位で指定すると膨大な数値になるため、十進法decimal systemは基準の千倍単位毎にk, M, Gを使う。情報通信分野では、2進法のため千倍ではなく千倍に近い数値で210の1024 Bを次単位に使う。1024倍も、その1024倍も十進法同様、k, M, Gという記号を使うが、混乱を避けるため情報ではkをケーと呼ぶ。1 MBメモリは、10242 (104万8576) Bメモリとなる 日本語漢字コードコンピュータは米国で生まれ、情報処理技術も初期段階では米国で開発発展し、普及初期には漢字使用に特殊な方法を必要とした。現在、JIS規格に日本語漢字取扱規格があり、殆どのコンピュータがJIS規格に従い日本語漢字を取り扱う。しかし、「JIS規格日本語漢字コード」とASCIIコードを混在させ通信を行なう際には、コンピュータ内部構造の違いやネットワーク対応方法の違いが原因となりJISコード、シフトJISコード(S-JIS)、日本語EUCコードの3規格が定められ、いずれも広く使われているメモリ安価になり利用可能漢字数増えたが全漢字を取り扱えるには至らない。漢字追加は問題が色々ある(追加文字選定基準、コンピュータ内割り当て時の既存文字との調整問題等)。アルファベットは文字数少なく、必要な全文字記号を最初にコード化した。コード対応順序はa, b, c ... x, y, z, A, B ...のように決めた。漢字を、亜、会、居、胃 ...と「あいうえお」順にコード化したとする。漢字「医」追加時に、単純に亜、会、居、医、胃···と「居」-「胃」間に「医」を追加すると、古いコンピュータシステムで作られた文章ファイルを新システムで使うと「胃」で書かれた部分が「医」と置き換わり、それ以降も全てずれる。かといって後のほうに追加すれば「あいうえお」順が崩れる Q JISコード表にない漢字を漢和辞典等から探し、その漢字をインターネット通信するにはどうすべきか Q どのような言語があるかを調べ、その言語の使用文字を画面表示やEメール送付する工夫せよ テキストデータとバイナリデータテキストデータ text data: 数字・記号・アルファベット等の文字コードのみから成るデータ。即ち、ASCIIやJISの文字コード → テキストファイル text file: テキストデータだけで出来たファイルバイナリデータ binary data: テキストデータ以外のデータ → バイナリファイル: そのファイル テキストデータは文字の種類と改行(CR)等の少数の機能コードだけを規格しているにすぎず、文字だけで情報をやり取りする際の最低限度の約束といえる。ワープロソフトを使い、文字の色・大きさ等の文字属性を指定したり、下線・罫線等の文字飾りをつけ見栄えのよい文書を作るが、これらのファイルや、表計算ソフトや画像ソフトで作られるファイルは普通バイナリファイルである 通信における文字符号化問題Eメールは複数コンピュータを中継し、中継サーバのどれかが漢字処理が異ったり不充分だと文字化けする。Eメールは文字コード変換を繰り返し伝送されるので、問題サーバの改善しか解決方法はないインターネット使用可能文字は、RFC等規格で定め、規格外文字番号使うと、通信相手に正確な内容が伝わらないばかりか、中継途中サーバ停止もある。読む人が正常に文字表示できるか注意し、文字選択すべき。ここでは、文字化け原因と文字化け防止通信の注意点を知る 文字化けは、異コード使用コンピュータ(通信)間やソフトウェア作成ファイル間のやりとりで起る。問題回避法に、「(文字)コード変換プログラム」利用がある |
外字問題JISコードは第2水準までで計6353字で、人名・地名、古字、中国文字等ではJIS未登録漢字が必要となるためFEPには普通、漢字(外字)作成登録機能がつく。外字は、16bで作られるビットパターンの内、JIS第1, 2水準未使用ビットパターンに割り当てされる。これらの文字はJIS規格文字コードがなく「外字」と呼ぶOS機能を使い、利用者自身が管理する。外字は登録した空領域に振り分けられコードはバラバラである。メーカー独自登録では、メーカー毎に異なる。外字は規格外世界で、JIS漢字コード未定義漢字を、「外字コード0001番」等と決める。利用コンピュータやユーザが異なれば、同じ文字番号が異なる文字に対応する。外字は必要上用いるので利用不可となるものではない。しかし、ネット-ワーク上で外字を送ると、まず正しく伝わらない。外字を使う場合、文字形画像ファイルを同時送信したりする必要がある。この問題点解決のためJIS漢字コード拡張が検討されている半角カタカナ問題 (8 bカタカナ)インターネット普及以前の低メモリPC規格で、利用も国内に限られ非国際規格で、今後普及はありえない。文字化けは、8b単位文字コードでカタカナと必要最小限の記号を扱ったことに由来する。半角カタカナ自体は全角の半分で字幅に注意し判別できるが、句読点「、。」や、促音「ー」、中グロ「・」などの半角カタカナ文字は、画面上では判別難しく注意が必要である
⇔ 全て全角文字: ABC12@? 日本語以外の漢字中国・台湾・韓国・北朝鮮漢字コードは日本語漢字と別コード体系を用い、JIS規格日本語漢字コードを解釈するOSを使わない限り、日本語漢字コードでEメールを送っても無意味となる。日本語コードで「我是田中」と書いて中国に送っても漢字割り当て番号が異なり無駄である。同様に、「全角文字」の英字アルファベットを使っても、英語を母国語とする国では読めない→ 「書き手の環境・読み手の環境に気をつける」。様々な言語仕様OSでコンピュータが動作し、同じコードを使っても、同じ文字が表示されると限らない。文字表示という基本問題だけでも、様々な問題を抱えるのが現在のインターネットである。コード系は、8ビット(1バイト)単位で符号化するものと16ビット(2バイト)単位で符号化するものが主で、それぞれ更に幾通りものコード系が存在する マイム MIME, multipurpose Internet mail extention: 7 bitコードのみ伝送のInternet E-Mailで、送信時に7 bitコードにencode、受信時に8 bitコードにdecodeし8 bitコード入り文書を送り8 bitコード送受信する仕組み Base 64: バイナリデータのASCII文字列変換方式の1つ。E-Mail添付ファイル変換等に使用 Q 世界中の言語を調べ、その言語の使用文字を画面表示したりE-mailで送受信する工夫を考えよ Q 1) インターネット利用を避ける文字特性を示そう。2) JISコード未対応漢字のインターネット通信法を工夫せよ |
|
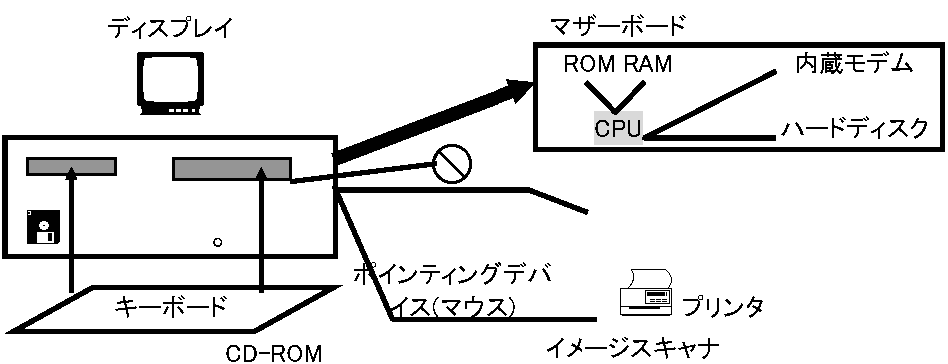
ハードウェアを「金物」、ソフトウェア中のプログラムを「算譜」と訳した時代もあった。コンピュータは、ハードウェアとソフトウェアがなければ動作できず、コンピュータを動かす車の両輪といえる → コンピュータ = ハードウェア + ソフトウェア ハード(ウェア) hardware: 見えるコンピュータ構成機器全て。Ex. PC = (外側: 本体、キーボード、ディスプレイ、マウス、CD-ROM、フロッピーディスク) + (内側: ハードディスク装置、マザーボード接続CPU、メモリ) ハードウェア = 入力装置 + 出力装置 + 中央処理装置 + 主記憶装置 + 補助記憶装置 ハード中央処理はLSI構成回路図が基本仕様枠組である。回路図(配線図) circuit diagram (schematic diagram)から装置動作まで把握でき可視性が保証される。一方、ソフト中のプログラムは、基本的仕様枠組は存在せず、流れ図flow chartを眺めても実現機能を殆ど理解できずソフトは不可視的であるハードは、装置や部品を利用目的に合わせ組換えできる。マルチメディアコンテンツ制作に、イメージスキャナやデジタルカメラを接続し、カラーレーザープリンタを接続する等である 表. OSの種類と特徴
OS UNIX WinNT Win98 MS-DOS
マルチユーザ ○ ○ × ×
マルチタスク ○ ○ ○ ×
階層型ファイルシステム ○ ○ ○ ○
標準入出力 ○ × × ×
簡便コマンド ○ × × ○
ソフト(ウェア) software: プログラムprogramやデータ(プログラムが扱う情報)等、コンピュータ作業をするのに必要なデジタル情報全般をいう。エディタ等を通し、プログラムやデータを覗いても、プログラミング言語やデータの意味を知らないと意味はない。プログラム作成の考え方(理論、概念、方法論、技法等)やドキュメント(仕様・設計・操作手引等)も含まれ、まさしく不可視であるPDF, Portable Document Formatは、Adobe開発のPostScriptを元にしたドキュメントフォーマットで、マルチプラットフォームで扱え、閲覧だけならAcrobat Reader(無償)が使える。テクTeXは、UNIX等で広く使われる文書整形システムで、初心者版にLaTeXがある。名前はtechnologyの語源を表す語源を表すギリシャ語に由来する ソフトウェア(アプリケーションソフト)を組合せ使える。画像データを画像処理ソフトで加工し、DTP(卓上電子編集)ソフトで編集します。自分でプログラミングする(命令文の組合せ)こともできる
ソフトウェア = 基本ソフトウェア(OS) + 応用(業務用)ソフトウェア
表. ハードウェア、ソフトウェア特性の対比 マルチメディア文書とその素材マルチメディア multimedia: コンピュータで扱うテキスト以外の情報の総称基本素材 Ex. 画像。サウンド(音)。動画: 高印象トな反面、情報量多でファイルサイズ大となる マルチメディア文書: テキスト以外の情報も含む文書テキストが基本で、それに他のものを加えるから複数種類の(マルチ)媒体(メディア)という マルチメディアコンテンツ(内容): テキスト情報を含まないものマルチメディア素材(コンテンツ材料)は通常、ファイル保存し取り出し利用する。特定種類のメディア素材でも、ファイル格納方法(や、メディア情報を01に対応づける方法)は一通りと限らず、ファイルフォーマットと呼ぶ。ファイル内容が分かるよう、ファイルには格納情報フォーマットに対応した名前(拡張子)をつけるのが通例である アプリケーション application (AP): ワープロ・表計算・アニメーションソフト等、各種ソフト固有のファイルを媒体(メディア)とし使うことや、任意プログラムを媒体とし使うこともある。APやプログラム独自の機能が使える利点があるが、どこでもアプリケーションやプログラムが動くとは限らない制約がある。ファイルフォーマットはAPやプログラムの動く環境に応じて様々である Q 情報を伝えるメディア種別を挙げ、コンピュータで(1)既に実用化、(2)研究中、(3)扱えるか不明、に分類せよ Q 用意された素材集を見てみよう。ファイルサイズと素材内容にはどのような関係があると思うか、考えよ マルチメディア文書設計多くのソフトで、マルチメディア文書はテキスト部分も、見出し・本文・引用・強調箇所等内容に応じ字体や文字サイズや色を変える等、表現工夫が可能である。マルチメディア文書は、テキストで表せないことを伝えるが、読手、書手の双方が各種メディアや表現等に目を奪われ肝心の内容が疎かになる恐れもあり、伝えたい内容を明確にし、文書構成を決め(普通文書設計法と同じ!)、それに沿い各種メディアや表現の使い方を決める |
各種メディアや表現の使い方では、次の点に気をつける
画像: 必要以上大きくせず図等テキスト表現できない情報を効率的に伝える。人物の顔を知らせるとか、確かに伝えようとしている出来事があったことを納得してもらう、等明確な目的を持って使う マルチメディア文書作成オーサリングソフト: マルチメディア文書作成に適したソフトウェア。テキスト打ち込みに加え、範囲指定やメニューを使い「見出」「箇条書」「N行M列表挿入」「素材(画像・音)挿入」と指示しマルチメディア文書を組立てるワープロソフト: 主にテキスト情報を使うソフトウェア → 画像挿入できるものが増え、両者の区別は現在曖昧 コンピュータ文書作成は「最終順序に拘らず作成できる」利点があり、書きたい所から本文を打ち込める。ソフトの「画像挿入」機能で、画像ファイル名や注記、配置等を指定し、画面に画像を取り込む。サウンド挿入は、文書にリンクを用意してリンク選択で音が出せる。別文書にジャンプするリンクもURL指定で同じく作れる。指定完了すると先に選択したテキストがリンクになる。表形式は、表作成機能を使う。オーサリングソフトで各種メディアを取り込み、色々な表現を持つ文書を作成できるが、本質的に、各種メディアはファイルであり、マルチメディア文書側には「このファイルをここに埋め込む/リンクする」という情報を(内部的には)記録する。ファイル形式によっては、他ファイル内容そのものを埋め込む 作成ドキュメントはHTML形式保存しエディタで編集できる。テキストには入力テキストそのものの部分と、入力テキストにないものがある。テキストにない部分は、『この範囲は』「見出し」「色」「表」という情報を表し、この内容(コンテンツ)に別情報を付加し表現や機能を提供することをバインディング(束縛)と呼ぶ。HTML形式同様、ワープロソフトはバインディングを付加しコンピュータで扱う多くのファイル形式も同様の考え方が見られる 表ソフト計測データ量が多いと、表(作成)ソフトウェアが威力を発揮し、
例題 運営問題は、過去データ参照し各競技必要時間を決めることである。表を順次作成せよ。基本データ表作成のため、大会番号、競技種目、開始時間、終了時間、参加選手数を資料から抽出し入力する。演算機能を使い、開始-終了時刻から競技所要時間を計算し表を完成させる
競技時間の元表 表. 競技種目別の競技時間
大会 選手 100m走 走り幅跳 400m走 1500m走 …
番号 合計数 (男女) (男) (男女) (男)
1 122 100 180 40 20 …
2 145 100 200 45 30 …
同競技を複数回に分け行なうものは合計時間を求め、競技種別毎の競技所要時間表を作成する選手合計数は大会に参加した実数であり、予選と決勝がある種目は予選数で計上する Q 表について 1) 大会と競技所要時間の関係を表示するには何グラフが適切か, 2) 選手数の多い順に並べる時、その手順を示せ, 3) 競技種別あたりの競技所要時間の最大値と平均を求める手順を示せ 例題 運営上の問題6 = 第1回大会から前回までの大会記録を整理し、各競技の大会記録表を作成する。歴代大会の資料から、優勝者記録を抽出し表を作成する。表はフィールド競技を集めたもの、トラック競技を集めたもので作る。表に基き、種目別記録一覧表を作成し表とする Q 各表から競技の種目毎の記録を大小順に並べ替える手順を示せ 例題 経費問題1 = 予算立案参考に、最近5年間の参加費・補助金・その他データ収集し表作成 例題 報告書問題の収支決算表を作成せよ。入金は、参加費、補助金、その他の欄を、出金は、人件費、会場費、印刷費、郵送費、その他の欄を設ける Q 運営上の問題5は参加者名簿作成であった。作業効率を上げるため、この名簿には8桁の個人コード項目を付けることにした。その他の必要な項目を決め名簿一覧を設計せよ |
|
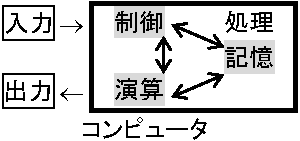
「コンピュータとは何か」 → 概念モデル(メンタルモデル)で解答可能 概念モデル(メンタルモデル): 実物・事象を理解する過程で形成される知識概念を抽象化したモデル メンタルモデル把握 → コンピュータ動作原理や仕組を知り、コンピュータ内部をホワイトボックスとして捉える → コンピュータに対し統制感を持った健全な利用者という立場を取れ高度情報化社会一員とし活躍できる Computerは、「(電子)計算機」と訳すが、計算道具という誤解が生じ技術革新につれ高度処理も実現し、訳さず使われることが多い。名前通り「数値計算高速大量実行機械」だが、デジタル情報(ビット列)処理(蓄積・加工)機械が実情である。コンピュータ分野では、訳の誤解や定着しない等の理由から多くの用語が片仮名で使用される。英語略称も用いられ情報処理分野では英語も必要である。背景に、コンピュータ関連技術の多くが英語文化圏から流入し、この打開に情報(処理)教育のあり方が問われている(デジタル)コンピュータ(計算機) (digital) computer: デジタル情報を蓄積加工する装置 ノイマン(Jhon von Neumann)型コンピュータ論理機械は、抽象的(論理的)仮想モデルで、物理的素材(集積回路等)を用い情報処理装置とし実現したのがコンピュータである。ノイマンアイデア実装ノイマン型コンピュータは、次の3方式を実現したコンピュータで最も普及した。論理機械の操作装置に記録される操作規則(個々の遷移関数)をプログラムと呼ぶ。論理機械の入出力媒体に記録される記号をデータと呼ぶ集積回路 integrated circuit, IC: チップに電気回路作る素子を組込んだもの 集積度(素子数)による呼称: Small scale integration, SSI < 100, Medium scale integration, MSI = 100-1000, Large scale integration, LSI > 1000, Very large scale integration, VLSI > 10000 1) 2元符号方式2元符号化方式: プログラムとデータを共に2進数列として扱うこと一般的にi桁n進数数値(N)を巾乗で表すとN = Ci–1·ni-1 + Ci–2·ni–2 + … + C1·n1 + C0·n0 (C仮数、n基数、i指数)になる。Cは0から(n – 1)までの値をとる。2進数は「n = 2」で、6桁の2進数abcdefは(abcdef)2 = a·25 + b·24 + c·23 + d·22 + e·21 + f·20となる。a-fは0か1である。コンピュータ内部では、情報(数値・文字・音声画像等)を2進数で扱う。数値は、10進数値なら(21)10 = 1·24 + 0·23 + 1·22 + 0·21 + 1·20 = (10101)2となる。文字は、2進数8桁なら(0000000)2に文字1、(0000001)2に文字2、… (11111111)2に文字256を割り当て、256種文字を割り当てられる Case. イメージデータ中で4 × 4桁2進数の組合せ 枡目中に黒を2進数の"1"、白を"0"に対応させ、1行目 = (0001), 2 = (0010), 3 = (0100), 4 = (1000)、(0001001001001000)2とし2進数列で斜線イメージデータ(/)が扱える。コンピュータでは、プログラム・データ共に任意の2進数列(ビット列)に変換される。コンピュータは、電子回路構成され、論理回路は電流オン-オフ状態組合せで動作決定される。電流オン状態を"1"、オフ状態を"0"とし、それぞれ2進数に対応させる 2) プログラム内蔵方式プログラム内蔵方式: プログラムとデータをコンピュータのメモリ(記憶装置)に記憶していることメモリ(記憶装置) memory unit: 主記憶装置 + 補助記憶装置 主記憶装置は、主に実行プログラムとデータの記憶装置で、比較的容量(数10Mメガbyte)が限られる。補助記憶装置は、さしあたって実行しないプログラムとデータの記憶装置で大容量(数Gギガbyte)である。実際には、プログラムとデータ(基本ソフトウェアと応用ソフトウェア)を補助記憶装置に記憶(インストールinstall)し、実行プログラムを選ぶ。選択すると、選択プログラムとデータが主記憶装置に移り(ローディングloading)、実行プログラムがコンピュータで稼動する状態になる  図. プログラム内蔵構成 ノイマン型以前のコンピュータは、メモリ相当機能が殆どなくコンピュータ指示手順は配線組替えやスイッチ組合等の物理的機構を用い逐次人間が外部から与え、複雑煩雑操作を人間に強いた。プログラムとデータをメモリ記憶し、利用者はこの作業から開放されコンピュータは一見自律的動作可能になった。JISコンピュータ定義で「… 人手の介入なしに遂行 …」の機能を持った訳である。「ある意味で自律的動作」とは、予め人間(プログラマ)がプログラム作成し、それを記憶装置に記録する前提条件があり、プログラムは欠かせない。コンピュータが、自己判断し処理遂行するのではなく、手順をプログラミングし与えた結果、利用者から自律動作に見える3) 逐次実行制御方式逐次実行制御方式 = プログラム実行は一度に1命令を順番に進める → 論理機械で言えば、操作規則が順次1つずつ処理されることで、複数操作規則を同時に並列的に実行できない。このような実行制御なのは、ノイマン型コンピュータは実行プログラムをただ1つしか指定できないことによる実行プログラムとデータがローディングされ(実行ソフトウェア起動アイコンクリック等)、主記憶装置に記憶される。その主記憶装置全領域に対し番地がふられ、番地で主記憶装置上の全ての場所が修飾されている。実行プログラム指定は、そのプログラムが格納された主記憶装置上の最初の番地に位置づけることになる。コンピュータでは、プログラムカウンタというカウンタ中にその番地が設定される。プログラムカウンタは、中央処理装置中に1つしかないため、ただ1つの命令しか取り出せない Q 2進数で符号化すると2進数が何桁必要か。1) 数字: 0-9の10種類, 2) アルファベット: A-Z, a-zの52種類, 3) 記号: 空白や特殊記号等38種類 IPOモデル「デジタル情報処理」は、コンピュータに備わる機能に他ならず、具体的は次の3機能が備わる
入出力: 外部とコンピュータとの間でデジタル情報をやりとりする機能(入力input/出力output)
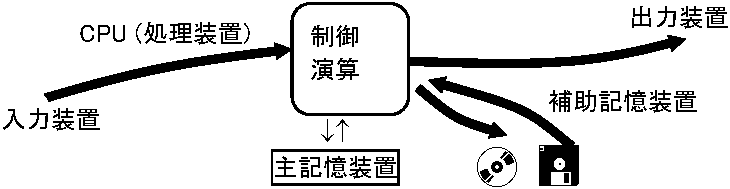
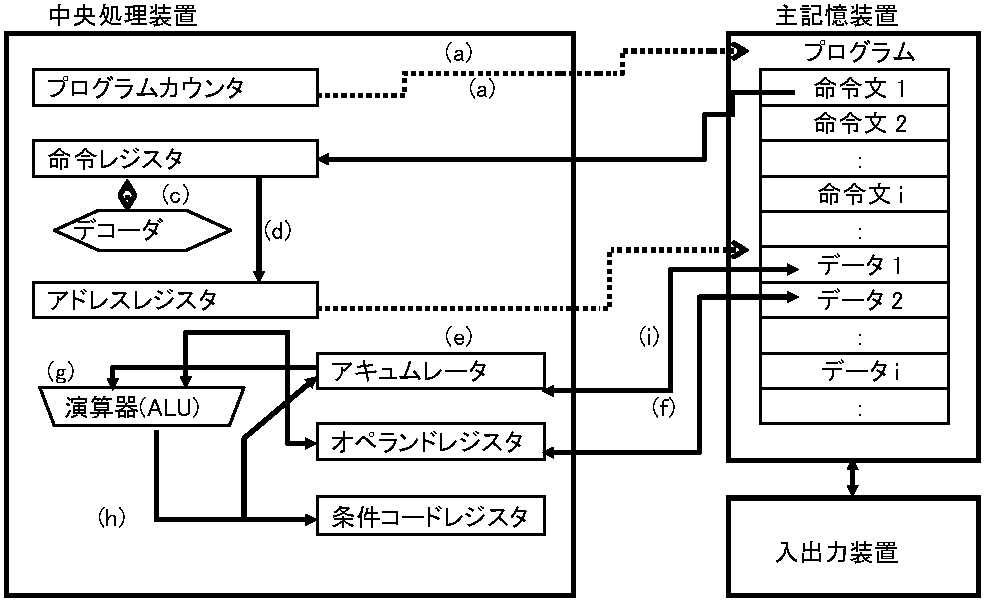
入力 input: 外部からコンピュータにデジタル情報を取り込むこと 出力 output: コンピュータから外部に情報を取り出すこと 入出力: 入力と出力 入出力装置: 入出力を行なう機器 1) 入力機能: コンピュータ情報は全て2進数に変換され入力 → 数の2元符号化(= 2進数表示) 正数 Ex. 正整数(i)で0から2i - 1の整数はαi-12i-1 + αi-22i-2 + … + α121 + α020 (αj = 0,1, j = 0,1,…,i - 1)より、αi-1, αi-2 … α1, α0と表せる Ex. i = 3 → 0から7までの整数 整数0 整数1__整数2___整数3_____整数4______整数5______整数6______整数7 __0____1_____10_____11________100________101_______110________111 _0·20 __1·20 _1·21+0·20 _1·21+1·21 _1·22+0·21+0·20 _1·22+0·21+1·20 1·22+1·21+0·20 1·22+1·21+1·20 負数: 符号ビットを付加する絶対値表現と補数表現とがある。絶対値表現は,絶対値を2進数に変換し,符号ビットを先頭に1桁付加する方式である。一方,補数表現とは,1の補数と2の補数を用い表す 一般に補数の定義は、Aをr桁のn進数とすると、Aの補数には、nの補数とn – 1の補数があり、A'(nの補数) = nr – A, A''(n – 1の補数) = nr–1 - Aになる。これより,10進数(n = 10)1桁(r = 1)の「8」の補数には,8'(10の補数) = 101 – 8 = 2、8''(9の補数) = 101 – 1 – 8 = 1がそれぞれ対応する。イメージ的には、「11 – 8」の減算を「8」に対し10の補数(= 2)をとり「11 + 2」の加算に置き換え、桁上がりを無視し「13」の上位桁を除き「3」とする。これより、減算を補数を用いた加算に変えられる。つまり、補数を用いると正負や値の大小に関係なく加算ができる 2進数r桁のAの補数には,A'(2の補数) = 2r - A, A''(1の補数) = 2r - 1 - Aがそれぞれ対応する。 1の補数は,A' + A = 2r – 1になり、基の数と補数を加算するとr桁が全て1になる。これより1の補数を求めるにはAの各桁についてそれぞれ1から引くことで求められる。1の補数は+0と-0が生じるためコンピュータでは2の補数を用いる。2の補数は,A' + A = 2rになることから基数と補数を加算するとr桁全てが0で、(r + 1)桁が1になる。これより2の補数を求めにはAの各桁について1から引いた値の最下位桁に1を加え(便宜的には各桁の0と1を反転し1を加える)求められる 表. 数値表現(2進数は8桁とする) 10進数表現 +3 +2 +1 +0 -0 -1 -2 -3 絶対値表現 00000011 00000010 00000001 00000000 10000000 10000001 10000010 10000011 1の補数表現 00000011 00000010 00000001 00000000 11111111 11111110 11111101 11111100 2の補数表現 00000011 00000010 00000001 00000000 (+0と同) 11111111 11111110 11111101 2進化10進符号: 10進数を2元符号化する時に10進数1桁毎に符号化を行う方式もある。10進数の性質をそのまま利用したいような場合に有効である。代表的なものに2進化10進符号(BCD)があり、10進数の1桁(0から9まで)を2進数の4桁(つまり,4b)とし表す方式である 2) 記憶機能 コンピュータにはデジタル情報記憶機能が必要。入力情報は演算実行まで記憶されねばならず、演算結果も記憶し、指示時に出力する。コンピュータ機器内の記憶実行部分を記憶装置 storage という。記憶装置は、高速出入可能だが容量が限られる主記憶装置 main storage と、低速でも大量記憶できコンピュータ電源切断後も内容が消失しない補助記憶装置(二次記憶装置) secondary storage に分類できる。主記憶装置は、メモリチップと呼ぶ数ミリ角半導体素子の集合で、1チップに64M-256Mb情報格納できる。補助記憶装置は、入出力装置の一種でもあり、計算機からの出力情報格納と、そこから取り出した情報は計算機への入力になる
回路 (circuit)記憶機構の実現方法(記憶の仕組)を取り上げる。コンピュータは、電子回路で構成され、最も基本となる電子回路が基本論理回路である。基本論理回路には、AND回路、OR回路、NOT回路がある
表. 基本論理回路の真理(値)表: 入力出力関係が一目瞭然になる。1: 入力・出力 = 電流オン
入力1 入力2 AND回路 OR回路 XOR回路 入力 NOT回路
0 0 0 0 0 0 1
0 1 0 1 0 1 0
1 0 0 1 1
1 1 1 1 1
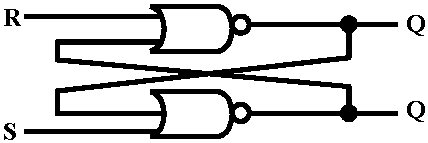
論理回路: 基本論理回路を組合わせて構成 組合せ回路: 入力(電流)状態に応じ出力状態が決定される論理回路 順序回路: 過去の状態とある時点での状態から次の出力状態を決定する回路で、直前入力状態記憶機構が必要で一時的記憶回路になる
基本フリップフロップ回路構成は、R, Sが入力,Q, Q'が出力である。QとQ'は、入力状態が変わらない限り同じ状態を維持する。入力状態変化時にQとQ'はそれぞれ0か1の値を持つ。S = 1(通電状態 = 電流が流れている)かつR = 0(非通電状態)の場合(セット状態)は、以前の状態に関係なくQ = 1/Q' = 0になる。それに対し、(S = 0)∩(R = 1) (リセット状態)では、同様以前の状態に関係なくQ = 0/Q' = 1になる。(S = 0)∩R = 0)では、Q/Q'に変化せず、そのままの状態が維持される。一方、(S = 1) ∩(Q = 1)では、Q = Q' = 1だが、次の状態でS = 0/R = 0になる場合Q/Q'値は確定せず、状態特定できず未定になる
表. フリップフロッ 主記憶装置(中央処理装置)に、実行プログラムとデータがローディングされる。いずれも任意ビット列(2進数並び)で構成され、ビット列は番地(アドレス)で修飾される。番地は、プログラム構成命令文を1つずつ取り出し、その命令使用データを取り出すメモリ上の格納場所指定ポインタである。実行プログラム起動するとメモリ上に配置された該当プログラム1行目命令文が格納されている番地が割り当てられ、該当プログラム実行が始まる。番地値は、内部的には2進数なため、その都度メモリ上の位置を2進数計算する必要がある。この煩雑さを防ぐためプログラミングでは変数を用い、番地修飾を記号化する。該当番地を示す変数を用い番地を求める計算が不要となる分プログラミングが簡単になる利点がある 3) 制御機能(演算制御) 中央処理装置(CPU)は、半導体素子で構成される。コンピュータデジタル情報入出力、記憶加工は、全て処理装置processing unitに制御される。つまり、処理装置には演算機能に加え、制御機能も内蔵されている。コンピュータが行なう具体的制御(コンピュータ全体としての動作)は、全てプログラムにより定められる。プログラムもデジタル情報(ビット列)で表され、主記憶装置中に格納されている。CPU中の制御機能は、主記憶装置に格納されたプログラムを参照し、その指示通りコンピュータ全体を制御する 演算: コンピュータ内部で(数値以外情報も含め)デジタル情報を加工すること 中央処理装置CPU (central processing unit): コンピュータ内演算実行部分 パイプライン pipeline: CPUの働きは、命令読込fetch、解読decode、実行execute、データ入出力storeと言った処理に分けられ、これらを流れ作業のように処理すること スーパースカラ super scaler: パイプラインを複数設け、並行し実行し、処理速度を上げる技術 縮小命令セットコンピューター RISC, Relesed Instruction Set Computer: 命令を整理統合単純化したプロセッサで、各命令実行はCISCより高速だが、オブジェクトプログラムが一般に大きくなる。処理速度向上に高速レジスタ個数を増やす等の理由で、質のよい最適化コンパイラを必要とする
Ex. PowerPC (Motorola, IBM, Apple), SPARC, Alpha (DEC), PA-RISC 以前はCPUと別にあり、増設する手段がとられたが、現在のCPUにはFPUが内蔵されている |
プログラム実行制御コンピュータ内部プログラム実行制御について、ハードウェア的側面、ソフトウェア的側面から取り上げる(1) ハードウェア的側面コンピュータが目的処理を(自律的に)実行するのは、処理プログラムとし予め与えている(プログラム内蔵方式)からである。コンピュータ本体には、CPU、主記憶装置、(内蔵型)補助記憶装置、電源等が組込まれ、その内の中央処理処置が、主にコンピュータ全体の実行制御を司っている
一連処理終了後、プログラムカウンタは(命令文1番地) + (命令文長)を自動計算し、次命令文2の番地を指すよう変わる。命令文が分岐命令や無条件分岐命令の場合、分岐先番地が設定される。こうして順番に1つずつ命令処理され(状態遷移、逐次実行制御)、最終的に停止命令により処理終了する DMA, direct memory access: CPU介さず高速にメモリにアクセスする方式 (2) ソフトウェア的側面ノイマン型コンピュータをIPOモデルにより機能化した際の制御機能相当部分がソフトウェアシステムである。基本ソフトウェア(OS)は、コンピュータ全体の実行制御管理し資源を効率的に使い利用者に使い易い環境提供、という目的で作られる。コンピュータは、様々な装置で構成され各装置を効率利用する仕組提供が第一の役割である。その上で、利用者がコンピュータの詳細な仕組や動作原理を知らなくても簡便に使いこなせるインタフェース提供が第二の役割となる。これらの役割を実現し、コンピュータは快適な道具(電子文房具)になるA. 基本ソフトウェア (オペレーティングシステム, OS) OSは、IPOモデルの制御機能をソフトウェア的に実現するソフトウェアである。OSは、一般的に中核となるシェル(コマンドプロセッサ)、と以下の1-6の各機能等から構成される。これらは、機械語変換された実行プログラムとして主記憶装置のOS常駐領域に予めローディングされる カーネル kernel: CPUの基本的制御行う、ファイルシステム等を除くOS核心部分。ハードウェア依存 → 通常アセンブラ記述 マイクロカーネル microkernel: カーネルで、ハードウェア依存の基本部分を切り分けたもの。OSをマイクロカーネル部とハードウェア非依存部分とに分けておけば、オーバーヘッド大きくなるが、特定ハードウェアに合わせてマイクロカーネルを開発するだけでOS移植できる 1) タスク管理機能 (シェル機能): タスク(仕事処理単位)効率管理機能。実行プログラムは、コンピュータ中でタスクに分割される。複数タスクがあると、それらを並行的に実行するため、更にプロセス単位で管理する。プロセス実行時、実行中プロセスと実行待ちプロセスを単位時間毎に分けた単位をスレッドと呼ぶ。CUPは、同時に1プロセスしか実行できないので、複数プロセスに割り当てるCPU時間を、それぞれのスレッドに割り当て切り換えながら処理を進めるマルチタスク方式が開発されたスレッド thread: タスクに似たのプログラム実行状態の1つだが、状態情報保持等をタスクに依存するだけ身軽でオーバーヘッドが少ない特徴がある。OS/2, NTは標準で、SVR4等のUNIXにも導入できる。 マルチスレッドmultithread: 1つのタスクtask (process)を、複数スレッドに分け並列に実行させること 2) メモリ管理機能: 主記憶装置領域管理機能。主記憶装置は、実行プログラム一時記憶領域に限界があり、全プログラムを主記憶装置に格納できないため、補助記憶装置のある領域を主記憶装置のように仮想的管理する方式(仮想化記憶方式)が採用された。補助記憶装置上にも実行プログラム部分を格納し、必要時に主記憶装置に転送実行する。実行プログラム分割単位がセグメントかページかによりセグメンテーション方式とページング方式がある3) データ(ファイル)管理機能: 主に補助記憶装置上に記憶するデータ(ファイル)アクセス管理機能。ディスク初期化、ファイル操作(新規作成・表示・印刷・複写移動・削除・属性変更・圧縮復元等)、アクセス制御(機密保護)、障害復旧等があげられる デバイスドライバ device driver: 周辺機器(デバイス)を接続、制御するためのソフトウェア 4) 入出力管理機能 (デバイス管理機能): OSのBIOS機能相当で各種入力装置input device (unit)と出力装置output deviceに対するアクセス管理機能。主に大型コンピュータがチャネル制御方式、PCがDMA方式使用
直接入出力制御方式: 初期コンピュータ実装 マルチウィンドウ、アイコン、プルダウン/ポップアップメニュー等の提供機能実現プログラム群 6) 言語処理機能: プログラム言語利用機能。各種プログラム言語と言語処理用言語プロセッサがある言語プロセッサは、プログラム言語をコンピュータ実行可能形式に変換する処理系である。高水準言語記述プログラム(原始プログラム)は、コンピュータが解釈できず、トランスレータかインタプリタを通し解釈する トランスレータ translator: 原始プログラムを翻訳し目的プログラムを生成するプログラム原始プログラムには、コンパイラ(高水準言語対象)とアセンブラ(アセンブリ言語対象)がある。作成された目的プログラムはまだ実行できず、連係編集処理を行い、実行可能プログラム(ロードモジュール)が生成される。実行可能プログラムは、機械語変換(コンパイル)され任意ビット列になり、コンピュータが理解する言語になる インタプリタinterpreter: 原始プログラム翻訳と同時に実行を行うプログラム簡単にプログラム実行できる反面、2処理(翻訳・実行)同時実行なためトランスレータより処理効率が下がる 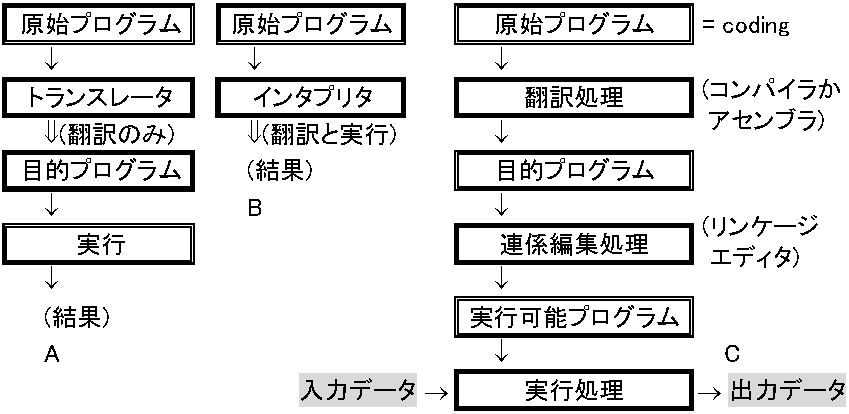 図. トランスレータ(A). インタプリタ(B). プログラム処理方式(C) コーディング coding: プログラムのソースコードを作成すること
低水準言語(計算機向き言語) low level language: プログラム言語体系が人間(プログラマ)より計算機(コンピュータ)に適し、人間から見て低水準言語となる。Ex. 機械語、アセンブリ言語 COBOL: 事務計算に適 BASIC, Beginner's All-purpose Symbolic Instruction Code: PC普及前、大型コンピュータ端末プログラム作成使用 文法平易で、初心者向け言語だが大きなプログラム開発に不向き Visual Basic (VB)
VBX: VB向けカスタムコントロール。VB以外の開発用ツールでも利用でき、汎用部品ソフトとなりつつある 構造化構文使い、プログラムをブロック単位記述でき、可読性に優れたプログラム構成できる。モジュール単位でプログラミングでき、複数開発者による大規模プログラム開発容易 C++ (Cプラスプラス)FORTRAN (フォートラン): 一般に使う数式に近い形で記述可能 → 科学技術計算向き Pascal (パスカル): 科学技術計算に適 Java (ジャバ): Sun Microsystem社がInternet上で使うことを想定し開発したオブジェクト指向プログラム言語 W3ページ上でJava言語で記述したプログラム(アプレット)を実行できる Ex. リアルタイムに株価情報受信しグラフ表示したり、商品購入数指定すると支払金額自動計算するページ
マクロ処理を記述できる。Internetで使うにはJavaインタプリタ内蔵W3ブラウザ必要 JavaとJiniにより実装する。主規定仕様 = アプリケーション枠組みとリソース管理、クライアント用API、ネットワーク上機器管理/使用に関するAPI、セキュリティ保持のためのAPI、データ管理API JIC, just intime compiler: Javaアプレットダウンロードと同時にJavaバイトコードをCPUネイティブコードにコンパイルする技術。Javaアプレットは、動作マシンの壁を越えるためJava中間コードファイルとなっている 実行毎に各CPUネイティブコードに置き換えると動作が遅くなるため、ダウンロードと同時にネイティブコードに置き換え実行毎のJavaコードのインタプリトを不要とし、結果的に高速動作になる API, application program interface: APからOS機能を使うためのシステムコール群のインターフェース仕様
通常Cのライブラリ関数機能として定義
C/S型システム管理ツールとMIFにより管理実現 MIF, management infomation format: DMIが使用するシステム管理用データベース データベース(照会)言語Ex. SQL, structured query language: LAN等で大規模DBを中-大規模コンピューターに記録し必要に応じ手元PCから必要データを処理するプログラム言語。分散DB検索可能が特徴 第4代言語(4GL, 4th generation language): 非プログラム専門家も容易に使える事務処理用言語。表記入形式事務処理用言語等だが、簡易言語やDB管理システムのマクロ等を含める人もいる。機械語を第1代、アセンブラを第2代、C等コンパイル言語を第3世代という時、この呼び名が使われる ソフトウェア開発モデル
B. アプリケーションソフトウェア (AP) = 繁用ソフトウェア + 特定処理用ソフトウェア (多くはパッケージ化) 繁用ソフトウェア
Ex. Microsoft Office, Lotus Super Office, Microsoft BackOffice等サーバー用スイートパッケージもある |
|
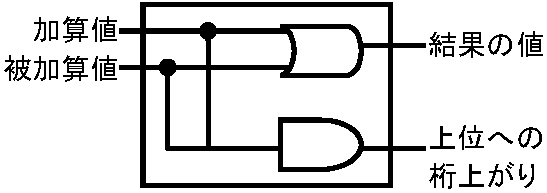
Boole G (1815-1864): 2離散数値数学 = 集合演算の持つ本質的な概念を抽象した代数 2つ以上の要素を持つ集合: 要素 = a, b, c, … (中には特別要素(記号) 0, 1を含む → 数の0, 1ではない) 演算記号: + (= ∨), •(= ∧), '(= ~) → 公理 (axiom) ネット情報検索では、積集合、和集合(又は)、差集合(-を除く)等の演算使える。「民宿又は旅館」なら「民宿」+「旅館」和集合、ホテルが嫌なら「宿泊施設」-「ホテル」差集合を使う。上で求めた集合と宿泊地を表す集合(これも和、差、積等の集合演算となる)との積集合を取るコンピュータ数値データ演算機能四則演算(和差積商) + 論理演算 + シフト演算 等四則演算和演算: 2進数1桁同士の和 → 0 + 0 = 0, 0 + 1 = 1, 1 + 0 = 1, 1 + 1 = 10(桁上がり) → 4パターン演算数と被演算数が共に"1"の時だけ上位へ桁上がり生じる 差演算: 2進数1桁同士の差 → 0 - 0 = 0, 0-1 = -1(借り), 1 – 0 = 1, 1 – 1 = 0 → 4パターン演算数よりも被演算数の方が大きい時は、負値になる。このため(10進数と同様)上位桁から"1"を借り演算を行う。ただし、実際のコンピュータでは、2の補数を用いた演算を行っている 積演算: 2進数1桁同士の積 → 0 × 0 = 0, 0 ×1 = 0, 1 × 0 = 0, 1 × 1 = 1 → 4パターン演算数と被演算数が共に1の時だけ1になり、論理積と同パターンになる。実際は(商演算も)シフト演算を用いる。シフト演算では2進数の各桁を左へn桁移動し、演算数を2nで乗算したことになる。同じく右へ桁移動すれば、演算数を2nで除算したことになる。以上の演算を、コンピュータは電子回路により処理する。記憶機能で取り上げた基本論理回路の組合せた論理回路には,組合せ回路と順序回路がある。そのうちの組合せ回路中に、半加算回路、全加算回路、補数回路等がある。これらの論理回路を用い、コンピュータは高速演算処理high speed computingを行う 半加算回路は、和演算を行う際に、下位桁からの桁上がりを無視し、上位桁への桁上がりだけに対応した論理回路である。このため、2進数1桁の加算しかできず、半加算回路と呼ばれる
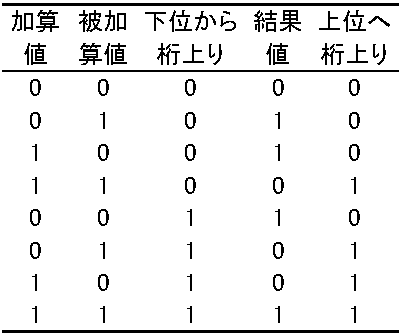
加算 被加 結果 上位桁 値 算値 値 上がり 0 0 0 0 0 1 1 0 1 0 1 0 1 1 0 1 これに対し、全加算回路は上位桁への桁上がりだけでなく下位桁からの桁上がりまで対応できる論理回路である。2進数n桁の加算ができるので全加算回路と呼ばれる。全加算回路の真理値表を示す 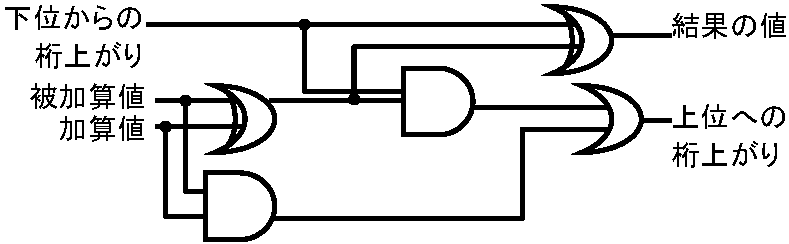 図. 全加算器の構成
表5 全加算回路の真理値表 出力機能(1) フォントシステム字体サイズ: ポイント(pt, 1 pt = 1/72 inchで表す → 72ポイント = 縦横1 inch字形: 文字の形 字体(フォント) font: 英数字・仮名・漢字等字種を統一的に決めた字形の集合 → 日本語フォント出力方式: ビットマップ方式、ベクトル方式が代表 |
ビットマップ方式: 字体を縦横ドットに分け、各ドットを黒色で塗るか否かで構成する方式で、このドットマトリックスをビットマップフォントbitmap fontと呼ぶ。ディスプレイは16 × 16ドット(高解像度ディスプレイは24 × 24ドット)を用いている。字体拡大時に斜線に凹凸が生じ見にくくなる ベクトル方式: ビットマップ欠点解消に開発された。ベクトル方式は、文字輪郭(アウトライン)をベクトル曲線で表す。文字アウトラインを、線・弧・曲線集合として数学的に表すためアウトラインフォントと呼ぶ。これにより、全字体の大きさ(ポイント)と解像度(ドット)に対応できる。これらのフォントシステムにより、ディスプレイやプリンタ等の出力装置の解像度が決定される ディスプレイ: 解像度は、画面「横方向ドット総数 × 縦方向ドット数」で表す。16 × 16ドット日本語フォントは解像度640 × 400は、横40字(640/16)、縦25行(400/16)表示特性(ノーマルモード)を表す。解像度1024 × 768は、横64行(1024/16)、縦48行(768/16)表示特性(ハイレゾリューションモード)を表す 解像度 resolution: dpi (dot per inch)単位 → 1 inchあたり桝目分割数]
1 point = 1/72 inch → ドットとは基本的には対応できない(ただし、一定dpiであれば同じドット数) Q フォントを24 × 24ドットとすると、JIS第1水準3000字。JIS第2水準 3500字の容量(KByte)は幾らか (2) カラー表示加色法と減色法: 基本的な色 elementary colors
RGB各点はドットdot構成され3ドットのまとまりを画素(ピクセル、pixel, px)といい、画像処理では普通pxを最小単位とする。白黒無階調画像は1 pxは「白黒」一方で1bで表せる。各色階調(発光有無)を取り(= 明るさ)表示色数範囲が増える。赤・青階調を5b (5段階)、緑階調を6b (合計16b)で表すと25 × 25 × 26 = 65536色可能だがカラー写真を鮮明表示困難で各色階調を8b (256階調)設定すると(28)3 = 224 = 16777216で約1677万色(フルカラー)表示でき写真を鮮明表示できる。カラー画像は1 pxの色や明るさを、「赤緑青」3原色の強さをそれぞれ0-255の段階(8b)で表し1 pxにつき24bを使うやり方が標準的
WYSIWIG, What you see is what you get: 画面に見たままの情報がそのまま印刷できること |
|
コンピュータ機能を1台のPCを想定しハードウェア面から見る コンピュータシステム基本的モデルに、論理機械が位置づけられ、状態と記号により動作決定される。論理機械に対し、実装アイデアを取り込んだものがノイマン型コンピュータで、IPOモデルにより機能単位に分けられる。各機能をコンピュータハードウェア構成各装置として実現したのがPCハードウェアシステムに相当
(1) 中央処理装置(CPU)IPOモデルの制御機能と演算機能をハードウェア的に実現するための装置中央処理装置中のレジスタやカウンタ、デコーダや演算器(ALU)等でコンピュータ動作機構制御する。CPU構成マイクロプロセッサmicroprocessor物理的特性が、コンピュータシステムの性能を決定づける。物理的特性の1つに、マイクロプロセッサ構成ビット数(データ表現ビット幅)があり、32-64 bに移行しつつある。もう1つは、CPUが1動作を行うサイクル時間単位周波数(マイクロプロセッサクロック周波数)で、高値ほど高性能だが、数百MHz(メガヘルツ)が主流で技術的に1GHz(ギガヘルツ)位が限界と言われる ミップス MIPS, million instrustions per second: コンピュータ実行速度表す値 → 1 MIPS = 1秒間に100万個の命令処理能力 → キャッシュメモリサイズ向上により、この方法では実行性能を正確には評価できなくなった SPECMark: ベンチマークテストによるCPU性能測定値 CとFORTRANで組まれた複数ベンチマークテストプログラムの各時間の相乗平均をVAX11/780 (≈ 1MIPSマシン)測定値で割ったもの。MIPS値に近いが、より信頼できる。整数演算性能のSPECint92、浮動小数点演算性能のSPECfp92、マルチプロセッサ性能のSPECrate_int92、SPECrate_fp92という値は、SPECmark値とは一概に比較できない ビデオチップ(画面表示専用半導体チップ) → マザーボード上にある グラフィックアクセラレータ(グラフィックカード、ビデオカード): 半導体チップではない専用拡張ボード デスクトップPCはグラフィックカード付け替え可能が普通。PCIバスとAGPバスとがある AMR Card, Audio/Modem Riser Card: Intel発表。マザーボード上にソフトモデム/オーディオ機能搭載機構マザーボード上にPCIバス接続専用スロット設け、DSP等を搭載したサブボード取り付ける。オーディオ/モデムのエミュレート処理は主にCPUが行う。Intelは、真のPlug & Play実現にISAバス撤廃を勧めAMRもISA撤廃の一役を担う。ISAバススロット搭載主な周辺機器は、サウンド、ネットワークカードだが、ネットワークカードはPCI対応製品が増え、将来ISA対応製品は無くなるだろう。しかし、サウンドとモデム機能にはISA対応製品が多いため状況打破に提唱された機構である。また、モデム/オーディオの専用ハードウェアを持たなくても良く、製造コスト削減にもつながる (2) 主記憶装置(RAM/ROM)CPUが直接アクセスするプログラム・データ記憶部分IPOモデル記憶機能の一部実現装置で、多くの主記憶装置はDRAM, dynamic random access memoryで構成され、コンデンサとトランジスタを1個ずつ用い電荷有無で1b記憶を行うRAM, random access memoryである。高集積度で大容量記憶可能な反面、再充電やリフレッシュ(自己放電のための再書込)動作が必要となる。(D)RAMは、読出・書込可能(リード/ライトメモリread/write memory)だが、電源切断時に記憶内容は消去される(揮発性メモリ)。DRAMは電源切断時に記憶内容を消去するため、初期化プログラム(BIOS, Basic Input Output System)等は電源切断時も記憶内容が残る不揮発性メモリのROM, Read Only Memoryに格納されコンピュータ電源を入れるとROM中BIOSを読み込みシステム初期化を行いRAMにアクセスする。ROMは読出専用メモリでROMにBIOSの他に各種フォントデータ等を組込む製品が多い。ROMやRAMは半導体メモリである RDRAM, Rambus DRAMは、Rambus社開発データ転送方法を単純化し、シーケンシャルアクセスを高速にしたDRAMである。転送方法単純化に伴い、データアクセスに必要な信号線も減らせる 主記憶装置容量は、格納実行可能プログラムの量質を決め、コンピュータシステム性能を決定づける特性である。ソフトウェアプログラムサイズは、多種機能実現のため大きくなる一方である。メモリサイズもコンピュータシステム性能を示す尺度になり64 Kbyteが主流 POST, power on self test: PC等起動時に行うメモリ・デバイス等各種ハードウェアの自動診断 DDR, Double Data Rate: RAMを1クロックで2データ出力し2倍のデータ転送速度を得る仕組 バス bus: PC用語では「通路」 = CPUと各装置間の転送路。バス数は、CPUビット数に対応し、32 bマイクロプロセッサCPUは1b情報転送バス数が16本で216の情報を転送 内部バス: CPU内通路 外部バス: CPU-外部装置間通路 (拡張スロット: PC機能追加のために、PC内部に拡張ボードを取り付ける部位)
アドレスバス: 主記憶装置や入出力装置の番地転送通路 PCIバス: IBM互換機に開発された方式。マッキントッシュも採用 普及バス中でデータ転送速度最速なのにデータ転送間に合わない → 高性能CPUやグラフィックアクセラレータではバスが狭く性能をフル活用できない カードバスCard BUS: 高速PCカード(PC Card Standard Specification)規格 PCIのPCカード版と言え、CPUとPCIバスで接続する。PCI Rev. 2.1と同じ、32bit幅、33MHz、132MByte/Secデータ転送を行う AGPバス, accelereated graphics port: ビデオカード用拡張スロットでマザーボード上 1966 Intel: 高速グラフィック専用バスとし発表(対応機器増) (3) 補助記憶装置IPOモデル記憶機能の一部実現装置これらの装置内記憶プログラムやデータは、主記憶装置に読み込まれ実行される。記憶方式別では、磁気(記憶)方式は、磁性体を表面塗布した媒体に磁気ヘッドで磁気変化させる記憶方式で、使用前に磁性体初期化(フォーマット format)が必要となる。大型コンピュータでは磁気ディスクや磁気テープ等がある。光磁気(記憶)方式は磁気とレーザーを併用する記憶方式で、光(記憶)方式はレーザー光を用い記憶内容を読み出す方式である ハードディスク hard drive: 磁気記憶式で記憶容量はG-T byte位 IDE, Integrated (or Inteligent) Drive Electronics: Western Degital社規定ハードディスク接続規格 最大約500MByteのHDを2台まで接続。元々、IBM PC/AT用規格だが、規格が単純で安価なため98やMac等でも採用された。現在IDEを拡張したEnhanced IDE (EIDE)が標準となる アタピーATAPI, AT Atachiment Protocol Interface: EIDEで、CD-ROM等HDD以外の機器接続用プロトコルATA, AT Atachiment: ANSIが規定したIDEインターフェース標準規格 ATA-1 ('88-94): 4台接続、528Mbye以上、リムーバブルメディア、ケーブルセレクト → ATA-2 ('93-95): 高速モード → ATA-3 ('95): ATAPIコマンド、SMART → ATA-4 ('96-97): ATAPI全仕様。データ転送速度16.6MByte/Sec → Ultra-ATA ('97-): DMA利用。データ転送速度33MByte/Sec フォーマット形式 format: ハードディスク等にファイル保存時に使われる形式• FAT, File Allocation Table: ファイル保存場所を一覧表様に管理。全OS可
FAT16: Win 95までの方式で2GBまで管理可能(2GB以上のハードディスク – 複数パーティション分割) |
フロッピーディスク floppy disk: 磁気記憶式。1.44 Mb(NEC1.2 Mb)。2HD(両面高密度倍トラック)フォーマット主流 (ほぼ消滅) ZIP: 高密度磁気ディスク。米IOMEGA社開発リムーバブルメディア。MO等に比べ安価でMDデータに比べスピードが速い利点 (ほぼ消滅) SuperDisk: 高密度磁気ディスク (普及せず) MO, magneto-optic disk: 光磁気記憶式。容量数百Mbyte。データ飛びあるがマルチメディアコンテンツ記憶に適 (ほぼ消滅) CD-ROM, compact disk-read only Memory: 光記憶式。CD-ROMはCD-DAと同じYellow Book仕様を採用し読込専用read only。追記可能(CD-R, CD-Recordable)、書換可能(CD-RW, CD-read/write, or 以前CD-E, CD-Erasable)、カメラ画像記憶用Photo CD、ビデオ用のVideo CDもある。(CD-DA, Compact Disc-Digital Audio: 一般音楽用CD。CD-ROM等コンピュータ用メディアと書き分ける時使用される)
CD-ROMアクセス方法 (4)入力装置IPOモデルの入力機能を実現装置コンピュータ外部からの入力情報を内部的に2進数変換し処理する。入力方式から次の装置区分がある キーボード: タイプライタが原型で、キー入力を電気信号変換し、コンピュータ本体で対応2進数に符号化される。キー配列は、QWERTY配列の(旧)JIS配列、仮名キー3段の(新)JIS配列、富士通開発の親指シフト配列、50音順仮名配列の50音配列等がある
OCR(光学式文字読取装置): 書かれた文字を読み取るのでコンピュータの前に座って使うには向かない イメージスキャナ: 画像データを、光学的に読み取りデジタルデータ(通常ビットマップ形式)に変換する装置。最大6400 dpi程度のものまである
TWAINは、HPやKodak社策定のスキャナ制御用APIで欧米中心に標準規格化した。初期に各社独自APIを採用したためAPソフトは個別対応となり、利用可能製品が限られた。TWAINは状況打開に作られ、入力装置・AP双方がTWAIN準拠ならメーカー・モデルを気にせず使える (5) 出力装置IPOモデルの出力機能実現装置 – コンピュータ内部処理データを、人間が分かるよう表示するディスプレイ CRT(Cathode Ray Tube)ディスプレイ: 電子ビームを走査させ蛍光体を発色させ情報表示 走査scanning: 画像を電気信号(映像信号)に変換する技術 液晶ディスプレイ: 偏光板で挟んだ液晶に電圧をかけ偏光させ情報表示DSTN, dualscan super twisted nematicは、単純マトリクス方式STN液晶ディスプレイの1種で、低コントラスト、低応答速度というSTN液晶の欠点を上下2分割し駆動し改善したが廃れた。TFT, thin film transisterは、アクティブマトリクス方式液晶ディスプレイの1種で、画面各ドット(画素)を薄膜トランジスタ(TFT)で制御する。現在の平面型カラーディスプレイ中、最も優れ、コントラスト、階調表示、応答速度はCRTと遜色ない
DFP, digital flat panel: Compaq, Apple, ATI等提唱の液晶ディスプレイ接続デジタルインターフェース規格 印刷時の物理的接触有無でインパクトプリンタ(ドットインパクト式)とノンインパクトプリンタに分類。後者に、インク液をノズル噴射し印刷するインクジェット式、サーマルヘッドで感熱紙焼きつけ印刷する感熱式、感熱インクリボンを用い普通用紙に焼きつけ印刷する熱転写式、光導電体を表面に塗った感光ドラムにレーザービームをあてトナーを付着させ印刷するレーザービーム式、ビームの代わりに発光ダイオードを用いるLED(Light Emitting Diode)式等がある (6) 通信装置コンピュータ同士で情報を送受信する機能実現装置モデム(変復調装置): 一般電話回線はアナログ方式なためA/D変換必要となる。モデムで音声信号audio singalに変換し電話回線経由で伝送し、向こう側モデムでコンピュータ用信号に再度変換するのは代表的通信方法である。デジタル信号からアナログ信号への変換を変調modulation、反対を復調demodulationと呼び、モデムはその合成造語である。性能尺度に通信速度、1秒間転送ビット数を表すbps (bit per second)がある PPP, point-to-point protocol: コンピュータ間で非同期通信ができるシリアル回線用通信プロトコル TCP/IP等各種プロトコルと組み合わせ使用できるのが特徴。ダイヤルアップIP接続で一般的 TAPI, telephony API: PCが電話機能を使うためのAPI ケーブル・テレビCATV, Cable Television or Community Antenna Television転送速度の速い回線を使用し、コンピュータ高速通信回線としての用途に注目される ケーブル・モデム Cable Modem: CATVネットワーク-コンピュータ接続用モデムCATVネットワーク未使用チャネルをコンピュータデータ用に割り当てる。下り方向(CATV局 → 家庭)データ転送速度は10-40 Mbit/secでEthernetよりも高速である。上り方向(家庭 → CATV局)転送方法に2種類あり、下りと同形式をとる対象型と、上りは電話回線等を使用し転送速度を落とす非対象型がある。W3アクセスは、殆どが下りなためコストが安い非対称型が向く CDPD, Cellular Digital Packet Data: セルラ(自動車・携帯)電話空チャネルを使用する無線データ通信システム通信は、空き時間に自動的に行われ、暗号化/圧縮技術を採用し最大19.2 Kbpsでデータ伝送を行う DSUとTA: デジタル電話回線にPC接続する場合モデム不要だが、DSU (Digital Service Unit)というデジタル回線接続装置とTA (Ternimal Adapter)が必要で、より高速通信が可能となるATM, Asyncronous Transfer Mode: データ転送多重化/交換方式で広域帯ISDN(B-ISDN)中核技術であった。53 byte固定長データ列「セル」を単位とし情報をやりとりした → ATM LAN (普及しなかった) Bluetooth: Ericsson, IBM, Intel, Nokia, 東芝5社発表の無線通信技術。Compaq, Dell, 3Comも技術開発参加 通信速度は1 Mbit/sec(データ/音声同時送信)で30 feet以内7台までと同時通信出来る。障害物があっても使え、携帯電話等も視野に入れたデバイスである。IrDAは、スピード(Max 4 Mbit/sec)だけが利点と言え、Bluetoothへの置き換えが進む可能性否定できない プラグアンドプレイPlug & Play (PnP)は、拡張機器を"つけてplugすぐ動くplay"で、マシン本体BIOS, OS, 機器とドライバ全てPnP対応が条件だが、IRQ・DMA等設定不要な規格である。MacintoshはPnPが通常である |
Unix (UNIX)開始 = login name: 利用者個々識別名 → loginpassword: パスワード → <passwd ↵> シェル変数変更 = 自分の環境作る → %set ↵: シェル設定見る (シェル変数: $を頭につけ参照できる)
Ex. year="2001" ↵ → cal 1 $year ↵ → 2001年1月の暦表示 終了 = logout: %logout, %exit, or %CTRL(^) + D [サーバ等は、他ユーザも利用 → 勝手に電源切らない] shutdown: 管理者(root)のみが行なえる
%shutdown ??? ↵ (ex. ??? = +10: 10後停止, = 16:00: 午後4時停止) set ↵: 検索パスを調べる。set path=(path name) ↵: 検索パスの追加 標準入出力: 様々な入出力(ディスプレイ,ファイル、プリンター等)に対応する標準エラー出力: 普通ディスプレイに割り当て ファイルシステム(ディレクトリによる階層構造) "/": 絶対パス名
/: root, /usr: directory, %pwd ↵: カレントディレクトリーの確認
/bin: 古くからあるコマンド
%cp file original name new file name ↵: copy
r: 読取り可 read パスワード保護: /etc/passwdにある – 書込み禁止。SUのみ変更できる プロンプトprompt: コマンド入力指示部 - %wc file name: ファイルの行数、単語数、文字数を表示 コマンド入力 input → シェルshell → kernel → 起動 スペース" ": 単語区切り。セミコロン";": コマンド区切り – 連続実行
シェルタイプ: プロンプト, 特徴, 開発元
*: 0文字以上の任意文字列 |
コマンド説明 %man –k(キーワード), -f(ファイル), [-][<セクション>]<タイトル>
%man cal ↵: 時計使用法説明される (man –f = whatis <command> ↵)
stty –a [System V] or stty all [BSD]: 端末設定を全て表示
%scale n ↵: 小数点以下桁数指定
演算子: 意味 %talk login name ↵: リアルタイム会話実行。Loginが外の場合はname@·middot;middot; %msg [n] [y]: 端末への割込許可の有無
%who -T ↵により利用者割込許可状況がわかる -: 禁止、+: 許可
1. Subject ↵ → 2. 文章 ↵ → 最後の行頭に"."を打つ( ↵)か、CTRL + d
<: 標準入力切換、>: 標準出力切換 %cat file name ↵ 画面エディタvi, jvi →
%vi + file name ↵: 英語エディタ
more ↵: ディスプレイ表示を1ページ単位とする ウインドウズCOM, component object model: MS策定のオブジェクト間通信プロトコル
OLEのクライアント/サーバ間通信に開発されたが、現在Windowsの殆どの機能がこれに従い実装される DCOM使用 → ClientのプログラムはNetwork経由でServerのOLE部品を使用可能 APM, Advanced Power Management: Microsoft, Intel策定のBIOS OS, Applicationを連携させ節電を行う仕様⇓ 95採用 → BIOS主体 ACPI, Advanced Configuration and Power Interface: 98採用低消費電力機構。MS, Intel, 東芝策定BIOS、OS、デバイスドライバ、ハードウェア等が協調電力管理し全PC接続機器低消費電力化図る |
コンピュータと計算機言語コンピュータは、情報をビット列に符号化しデジタル情報とし取扱う。情報の種類として「人間から計算機への指示や意思伝達」を考える。人間同士で指示や意思伝達する時には、日本語等の言語(自然言語)を使うが、コンピュータに対し次の問題がある
自然言語は複雑で、指示や意思を表現したものをコンピュータで取り扱うことは難しい SGML, standard generalized markup language: ISOが定めた国際標準規格マークアップ言語 HTML基本構造HTML (HyperText Markup Language): W³ページ記述用マークアップ言語。「見え方でなく意味を指定」Ex. 「見出し」は、「大文字で表示」ではなく「見出し」と指定 → 見え方は環境毎に変わり、文字サイズが1種類しか使えない環境用ブラウザは見出しを下線表示したり反転表示し見出しらしく見せる HTML記述(コード)の基本形 = 1行目はDOCTYPE宣言で準拠企画(HTML 4.01とか)を示すタグtag: HTML記述の「< … >」の部分 タグは更に、開始タグ(Ex. <html>)と終了タグ(<</html>)に分かれ、一対の開始終了タグで挟まれた範囲を要素(Ex. HTML要素)と言う。HTMLは要素中に別要素を含められる。例ではHTML要素中にHEAD要素とBODY要素がこの順で含まれる。HEAD要素内側をヘッダといい、ここにW³ページ要約情報を記述する。一方、BODY要素内側を本体といい、ここにページ内容(ブラウザ窓中に現われるもの)を記述する XML, eXtensible markup language: W³Cが仕様策定を進めるW³等で使用する文書記述言語 W³用途が、DB管理システムとの連携等を通じ拡大し、HTML仕様に限界がみえたため作られた スタイルシート(style sheets, SS)→ 普及版 Cascading Style Sheets, CSS) HTML 4.01は、論理的構造と表現の両方指定は文章利用時、邪魔なため併用は非推奨であるEx. HTML表現指定すると、見出だけ取り出し目次を作る時、<h1> … </h1>中を取り出すと色指定タグが混ざる。即ち、HTML 4.01は、HTMLそのものは文章論理的構造指定に用い、表現指定にSS指定方法を併用する方針である。SSは、「<h1>は全てゴシック体」とHTML各要素単位で表現指定する機能である。CSS(直列SS)を見る CSS指定方法HTMLでCSSを使う場合、3通りの指定方法がある
スタイル定義は"セレクタ, セレクタ, … -規則; 規則; … ;規則"形式で、個々の規則はプロパティ: 値となる。ページ背景を薄青なら、セレクタBODYにbackground-colorプロパティを指定する Ex. BODY - background-color: #CCCCFF" H1とH3の全見出しを青枠にするには、borderプロパテイにsolid、border-colorプロパティにblueを指定 Ex. H1, H3 - "border: solid; border-color: blue" CSSの主なプロパティcolor: 文字等色指定background-color: 背景色指定 border-style: 縁指定 (solid, dashed, double, groove, ridge) border-width: 縁幅(幅・長)を10 px (pixel), 8 pt (point), 12 mm等単位指定可 font-size: x pt等かxx-small, x-small, small, normal, large, x-large, xx-large指定 text-align: 揃え。left(左寄), right(右寄), center(中央揃え) line-height: %で行間指定 (200% = ダブルスペース) text-decoration: 飾り (underline, line-through, blink (目障り最少限度に) margin-left/-right: 長さ。左右マージン(余白)指定 Ex. H1 - text-decoration: underline", P - text-indent: 20px; border: ridge", UL - background: #CCCCFF" Q 作成ページにスタイル指定入れ、タグ指定や色指定変更し、次にスタイル機能をSS定義に追加せよ。各プロパティはどの様な目的に利用できるか スタイル設計スタイルは、「目立てばよい」では派手でも内容伝わらず逆効果 → コンテンツ同様、気ままにスタイルをつけず、次の事柄を参考に予め設計すべき
スタイルの目的は読手に内容伝わりやすくすることと考え設計する 個別的スタイル指定スタイルを「全H1」、「全P」とタグ毎指定したが、「このH1は赤」という時は、セレクタとしてタグではなく「クラス」指定する。クラス名指定時は、先頭にピリオドをつけ.important{color: red; font-size: x-large}と指定する。タグはclass属性でクラス名(ピリオドなし)を<h1 class="important"> … </h1>と指定する。こうすると、そのH1見出しは通常のH1スタイルに加えimportantクラス指定されたスタイルが追加適用される。しかし、まだスタイル適用範囲はタグ範囲と一緒である。そこでHTMLは、スタイル指定に2つのタグを用意している<div class="…"> … </div>: 段落等を含むブロック範囲指定 <span class="…"> … </span>: 文字範囲内指定 Ex. <p>本件は<span class="important">重要</span>な…</p> spanは段落内側に、広範囲(複数段落、箇条書、見出等)を囲むにはdivを使う要素の独立配置ある要素にスタイルをつけても、置かれる位置は他要素との関係で決まるが、SSで要素にposition指定すると、その要素を本来の位置からずらしたり、他要素と独立に任意位置に置いたりできる
position: 位置指定を行う。relative(相対配置、top/left プロパティで本来の位置からずらす大きさを指定する)、absolute (独立配置: top、leftプロパティで画面上の位置を指定する)が使える スクリプト人工言語(プログラム言語): プログラムに使用する言葉スクリプト言語: 簡単動作を平易に書く言語 → スクリプト: 書かれたプログラム Ex. ジャバスクリプト JavaScript WSH (Windows scripting host): 98搭載インタプリタ形式スクリプト言語。Win上操作をバッチ的実行可。DOSの*.batに似るが自由度広い 例題: ボタンを押した回数を数える |
「押して!」ボタンを押す度、回数欄数1増 <script> … </script>中にlanguage属性で使用プログラム言語指定(Ex. JavaScript)しプログラム書く。タグは<head> … </head>内側に書く <form> … </form>間が1フォーム(入力欄やボタン等の集まり)。Ex. 回数表示に、入力欄、回数を増やす動作のためボタンを使うので、これらを含む範囲を1フォームにする <input type=text value=1 size=5> 5文字分入力欄作り、初期値1を入れる <input type=button value=" …" onclick=" …"> ボタン作成。ボタン中にvalue属性指定がラベル表示され、押すとonclick属性指定動作実行 フォーム要素配置は<br />等タグを、説明等表示もテキストを書けば済む。Ex. onclick="keisan()"と指定しボタンを押すとスクリプトkeisan命令列(関数)を実行 → <script> … </script>内側で定義 document = スクリプト中のページ全体を表す名前。「.」は「-に属する」でdocument.forms[0]は「頁0番フォーム」を指し、n個のページはdocument.forms[n – 1]と指定 document.forms[0].elements[0] = 頁中フォーム最初の部品(例では入力欄) field = 入力欄名をfieldとする。次行で入力欄を扱う field.value = 入力欄に入る内容(文字並び) parseInt( … ) = 文字を整数値変換する。「+1」は、その値に1を足す field.value = 計算値を入力欄内容に入れ直す → これにより入力欄値なくなり、計算結果が入力欄の新内容になる 例題: 華氏を摂氏に換算1番目欄に華氏温度入力し変換ボタン押すと2番目欄に摂氏温度が表示される。html部分は、入力欄が増えただけで前と同様少数点計算するので実数変換するparseFloat( … )使う。2つの欄名をkashi, sesshiにする(計算: 華氏 → 摂氏)。プログラミング言語では普通、割算「/」、掛算「*」で表す。最後に、計算結果を欄sesshiの値として設定すればOK Q 例題を打ち込み動かせ Q 摂氏華氏変換機能をつけよ (ヒント: 関数追加と新ボタン) 例題: 最大公約数計算 (やや複雑な反復計算)2数値を入れ最大公約数 greatest common divisor, GCD (x, y)を求るHTML部分は、入力欄が増えるが前と同様である。スクリプトは、入力欄だけでなく2数値もxと yという名前で使う。while(条件) { … }は、「指定条件成立中、… 部分を繰り返し実行」動作になる。条件は「x! = y」で、xとyが等しくない間繰り返す、意味である。「指定条件成立なら(a)、不成立なら(b)を実行」する動作で、x > yならxからyを引いたものをxで表す。逆にyがxより大きい時はyからxを引く。この繰り返し部分は全体では「xとyが等しくない間、大きい方から小さい方を引くことを繰り返す」動作になる
x = yなら、xとyのGCDはxである CGI (Common Gateway Interface)UNIX環境前提にNCSA開発、標準入出力リダイレクションにより通信行うW³サーバのプログラム起動方法(環境変数名・値)規定仕様名称で、プログラムをCGIプログラム、スクリプトをCGIスクリプトと呼ぶ。主にPerl記述だが、環境変数と標準入力を参照し、標準出力できればC, C++, VB等も可。CGIで、通常HTMLページ表示に加え、カウンタ・チャット・掲示板・投票等ページができるCGI処理の流れ
Web_→ 要求 →__W³__→ 起動 →__CGI__
プロバイダが用意したCGIしか利用できない エディタでtest1.cgi名で作成保存する。1行目の#!後にperlパス名を記述。#!の前に空行や空白文字入れない。print " … "; というperl構文中では<body>タグ等で使用するダブルクォーテーション(")は、\"と記述する 一部プロバイダ(NCSA httpd, Apache利用サーバ)は、CGI動作にCGIスクリプトと同ディレクトリに.htaccess名ファイルを用意。.htaccessの中身は AddType application/x-httpd-cgi .cgi↵ と記述。既に.htaccessファイル設置されていれば、そのファイルに次の行を追加する(改行を忘れると.htaccessファイルは正常機能しない) CGIスクリプトと、必要なら.htaccessを、改行コードが適切となるよう[テキスト]か[ASCII]モードで、サーバ転送する。UNIXサーバは、CGIスクリプトのファイルパミッション変更が必要で755 (rwxr-xr-x)に変更する <CGI呼出>は、サーバ転送したCGIスクリプトをHTML同様、URL指定しブラウザで呼び出し、動作確認し設置完了。#!/usr/local/bin/perl やprint "..." 等のCGIスクリプトが見える場合は、サーバーが非CGIサポートか.htaccess ファイル設置必要。サーバ上に設置したURL (http://~)を呼び出しCGIは動作する パミッション(許可)とファイル属性Unixではパミッションと呼ぶファイル属性により実行可不可決まる。ファイルへのアクセス権は3種のユーザ種別、オーナ(自分)、グループ、他(人)毎に、読込(r)、書込(w)、実行(x)の権限が割当てられる。ディレクトリに対する実行権(x)は、そのディレクトリに新規ファイルを生成できる権限になる表. パミッションとファイル属性 読む 書く 実行 = 644 読む 書く 実行 = 666 読む 書く 実行 = 755 オーナー 4 2 0 = 6 4 2 0 = 6 4 2 1 = 7 グループ 4 0 0 = 4 4 2 0 = 6 4 0 1 = 5 その他 4 0 0 = 4 4 2 0 = 6 4 0 1 = 5 アクセス権には次の様な数字が割当てられている。読込み(r = 4)、書込み(w = 2)、実行(x = 1)。許可を数値で表す場合は、以下の様に各権限者毎の3アクセス権合計数値を並べて表記する 644: オーナー(自分)だけ読み書き可能、他ユーザーは読みこみだけ可能
HTMLディレクトリに、自分は読込・書込可、グループや他人は読込のみ
CGIの使うデータファイル(掲示板のログ等)は訪問者が誰でも書きこみ出来る様に設定する
CGIファイル更新できるのはオーナのみ - 誰でも実行出来る様に設定 Perl (JPerl: 日本語版 → Perl 5.6以降は日本語対応 = JPerl不要なはず) |
数値的モデル数値処理には判断や繰返しの必要条件を組合わせた問題がある。Ex 催し企画問題問題1. 直接的方法起こりうる全ての場合を調べることが可能な時2. 起こりうる全事象を調べるのが不可能な時天文学的組合せ数 → コンピュータでも計算に膨大な費用と時間a) ダイナミックプログラミング dynamics programming f(i, j)をPからi段階のj状態に行く最小のコストとする
枝途中で問題解決最適解と違うことが判明した段階で処理中断する方法 → 選択肢始めの方で組合わせの向こうが判別できれば処理は飛躍的に向上 最適性原理 (principle of optimality)多段階決定における最適政策基本原理 (Bellman 1953)最適政策: 初期状態とそれに対する最初の決定が何であろうと、残った決定は最初の決定から生じた状態に関し最適政策を構成せねばならない性質を持つ 最適分配 optimal allocation → 分配問題: 資源iを要求jに割り当てn個の資源をm個の要求に分配すること
コストテーブル cost table (effectiveness matrix) 3. 分割法 divisive method問題の難易はある程度大きさに関係 → 問題を小さく部分分割し、各部分解を見つけ、それらを結合し全体解を得る方式再帰的: 部分問題が元問題の縮小版の場合 漸化式関係: 元問題がn次元問題で部分問題がnより小次元の問題の場合 a) 再帰法: 次レベルに移る際、前のレベルの値を使い計算(淵上 1987) (フラクタル構造プログラミングに必須) b) 漸化式
a11x1 + a12x2 + … + a1nxn = b1 (1) Ex. コンボルーション: ある同一結果発生全ケース組合わせを数え上げる – 数増えると計算量爆発的増大 Ex. ある商品の毎日の売り上げは確率的で、1個が30%、2個が50%、3個が20%である。2日で売り上げる個数の確率をそれぞれ求めよ → 1日i個売れる確率をf(i)。L日間にT個売れる確率φL(T)を求める → 解法: L – 1日の売り上げ分布がわかればL日での売り上げ分布が求まる 4. 反復法近似解を逐次改良し十分な解に達したと判定できるとき、処理終了しそれを解とし取り出す方法
1 = 最初の近似解, 2 = 反復中の近似解改善法, 3 = 処理終了判定基準 f(x) = 0 の根を求める近似解法
_______[ 初期値 x0 ] → x1 = x0 – (a – x02)/(-2x0) = x0/2 + a/(2x0)  b) ヤコビ法: 二直線の交点を求めるに際し1直線上の任意の点を初期値とし、軸に沿って他直線上の対応する点に移動することの反復により解を求める方法
b) ヤコビ法: 二直線の交点を求めるに際し1直線上の任意の点を初期値とし、軸に沿って他直線上の対応する点に移動することの反復により解を求める方法
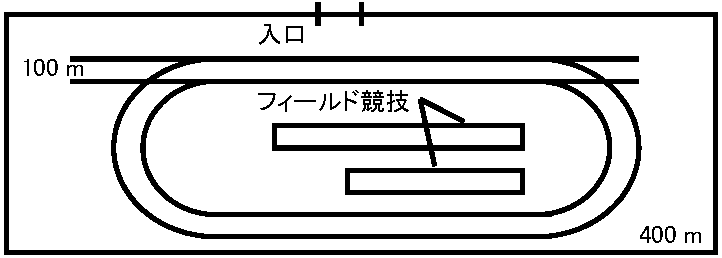
a11x1 + a12x2 + … + a1nxn = b1 → ヤコビ法でx2(k + 1)を求める際に、右辺に表れるx1の値はx1(k)ではなく直前に求めたx1(k + 1)を用いる 普通用いられる収束判定基準 Σi=1n|(xik – xik-1)/xik| < nε 5. 経験則 hulistic approach有効解となる候補群部分集合を基準に従い選び(条件付/仮定)、その中を調べ一番良いものを選ぶ方法の総称。最適解が選られるとは限らず、候補群選択サブルーチンが精度効率を決める数値計算と近似値例題 運営上の問題の案内中にグラウンドレイアウトを入れる(図1)
|
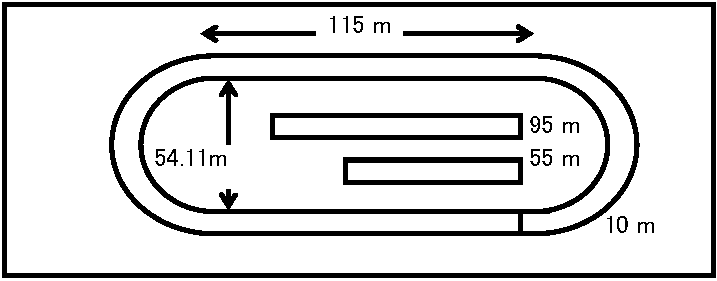
陸上競技場400 mトラックは直線部幅10 m、長さ115 m以上必要。曲線部幅は10 mと決めてある。走幅跳と三段跳は、助走路長45 m以上、幅1.6 m以上、砂場長8 m以上、幅2.8 m以上の条件がある。砂場と踏切板の距離は、走幅跳が2 m以上、三段跳が13 m以上である(図2)。トラック曲線部に半径rの半円を使うと(400 – 115 × 2) = 2πrからrが求まる。πが3.1415なら直径近似値は54.114となる
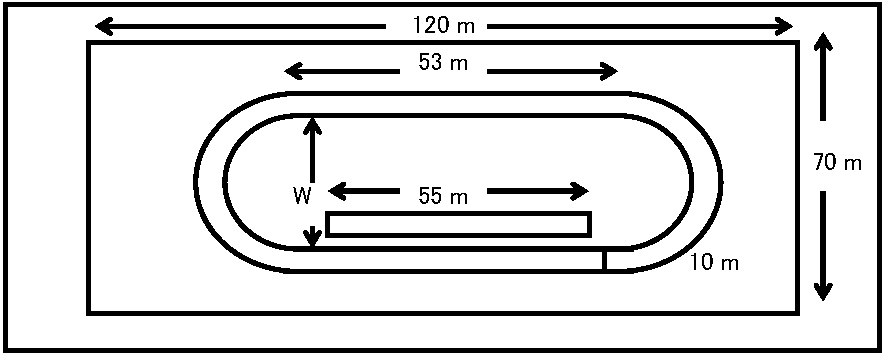
Q レイアウトを図3のよう描くとwは何mか Q 図3のグラウンドに200, 400, 1500 m競技ができるようスタートとゴール地点に白線を記入しコースを完成させよ Q 200 mトラックのドーナツ部分面積を求めよ
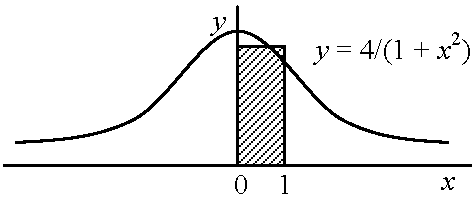
例題 π = ∫014/(1 + x2)dx → 右辺の数値計算によリπの近似値を求めよ 近似式: 数値計算では、変数xの任意関数f(x)における区間0 ≤ x ≤ 1の面積(≡ ∫01f(x)dx)を求める際、よく用いる
∫01f(x)dx = Σk=0n–1f(k/n)·(1/n) → π ≈ Σk=0n–1[4/{1 + (k/n)2}]·1/n 2) 台形公式: n等分した点を直線で結び、台形の面積の和を求める
y = f(x), a ≤ x ≤ b, ∃yk := f(xk) (k = 0, …, n) →
a ≤ x ≤ bを2n等分し、h = (b – a)/2nとし フーリエ解析Fourier analysis音声は、振動周波数とその強弱の時間的変化情報にでき、フーリエ変換 transformation (transform) が解析に用いられる。計算機上は、離散フーリエ変換 DFT, discrete Fourier transform アルゴリズムを用い変換する。1の原始n乗根(n乗し初めて1になる数)をwn、(p, q)成分をとするn次正方行列をAとするとAがフーリエ変換である。xをn次列ベクトルとした時、x(データ)にAを作用させ得られるn次列ベク トルyがフーリエ係数列である。[Ex. 音声データ f(m) (m = 0, 1, …, n – 1)]。計算量は、N個のデータに対しO(N2)となり、改良版が高速フーリエ変換 Fast Fourier Transform, FFT というアルゴリズムで、計算量はO(NlogN)となるピリオドグラム periodogram: フーリエ変換の振幅を2乗で表現したもの 情報処理定式化とデータ管理
コース1 /___\ コース2
競技種目 100m走A 100m走B 200m走 300m走 100mハードル走* 200mハードル走* A 方法1は、全体終了に2時間かかる。この説明を、「実際コースを割当て、スケジュールを作る方法」の形に書き直せ。割当ては、大会開始時刻から始め時間を順に追って行なうことが必要になりる。即ち
最初0分と書く → 大会開始時点競技割当を行う → 0分を15分に直す → 開始後15分の状況での割当作業を行う … のように進める 上記2で1競技が終わってコースが空いても開始できる競技が無く、コースが暫く空いたり、その後で再度そのコースで競技開始になる等の場合もあるため「このコースは今空き」という印を作り、そのための場所も用意する
_現在時刻________コース1__コース2__コース3__コース4 |
|
データ保管管理 : 情報整理 - コンピュータによる大量データ処理 データ構造 data structure: 使用目的に沿い便利なように情報相互間を関係づけたもの 処理手順を示すアルゴリズム効率はデータ構造に左右され、データ整理・保管・活用、管理技術が関与 表作成Ex. 郵便物配布必要情報データ種類
1. 相手の住所、郵便番号・所属・氏名 3. 差出年月日
疑問分類: 1) フィールド長(フィールド幅), 2) 文字列 文字列: 数字、アルファベット、かな文字、漢字、その他の記号からなる列。数字のみ文字列は、一般にコードとして使用される。郵便番号は普通は数値処理不要なため文字列として扱うことが多い Q フィールド幅や文字列を定義し、見易い表となる住所録ファイルを完成せよ Q 住所録を拡張し、電話番号欄を追加し、次にEメールアドレスを付加せよ データベースファイル構造を使い易く設計する。検索に注目すれば、フィールド順番入替が考えられ、事前に決められる。初めから順番を決めデータ入力するのは大変なので、一度入力したレコード順番を入替える仕組を作る。Ex. 表作成ソフト → 膨大なレコード数持つ表は表作成ソフトでは負担大きく大量データ管理システムとしてデータベース database (DB)開発コンピュータにより、大量データ蓄積・迅速加工が可能で、通信技術との融合が遠隔地情報処理も可能にし、コンピュータ情報処理は、時空間を越え行える。データの効率的保管方法を考えよう。基本データには数値や文字列の他、「真」「偽」で示される論理値表現もある。図形や画像、音声や楽音等をデジタル表現したデータもある。これらのデータは、全て0と1の2進表記がなされ、情報再現のために、その型式やフィールド長等構造を示す情報も記録されます。それぞれのファイルはスキーマに従ってデータ記述される スキーマ schema: データの型式等制約について論理的構造を記述したもの アクセス access: レコードを参照すること アクセスするのは、ファイル構成レコードである。レコード構成データ項目は、いつも同目的参照する訳でなく、同データが多目的利用されるため、ファイル検索更新等の操作が容易な登録簿を用意しファイル保管場所がわかるようにしている。プログラムとデータには相互関係があり、プログラム毎にデータを備えるのは非効率的である。データ蓄積労力からも、コンピュータ記憶領域からも無駄が多い。同データが幾つかのプログラムに分散すると、データ修正必要時に関係全ファイル所在を探しデータ変更する膨大な作業が発生する。重複データ間で矛盾が起こる危険性もある。これらの欠点を排除するため複数ファイルをまとめた多目的利用対応が考えられ、このファイルの集まりをデータベース database, DB という。DBは、プログラムと独立に整理したデータを蓄積し、条件合致データを検索し抽出できる仕組を備えたデータ基地といえる データベースの特徴多目的利用は、1)データとプログラムは独立(独立性)、2)データ重複ない(一貫性)、3)DBが安全かつ完全(安全性・完全性)なことが必要である。これらの特徴を維持管理し、利用者とのインタフェースを備えたシステムをデータベース管理システム(DBMS, Database management system) と呼ぶ。DBMSとデータ集合を合わせデータベースシステムというDBMSに必要な機能 (主機能):
データベース(DB)構造DBデータ表現形式: 利用者が使い易い構造で、コンピュータに少記憶容量で格納できるものが望ましい
外部スキーマ: 個々のプログラムに対応する外部レベル(利用者視点)のスキーマ
利用者視点 → [外部レベル → 概念レベル → 内部レベル] → 内部装置 データベースソフトウェアDBシステムは、大量データ蓄積のため考えられ、大規模コンピュータからPC上で使えるものまである。DBソフトウェアの多くは、次の機能を持つ
1. DB構造設計機能
5. テーブル複写機能 ⇒ Ex. リレーショナルデータベース
データ構造設計→表作成→データベース登録→
Q クラブ活動案内を、カード型DBで整理する時に備えておくと便利な項目をあげレイアウトを考えよ データベース設計DBソフトウェア利用で、利用前データ収集整理とDB設計は重要作業である。表作成時同様、データ項目選定し構造型式を決めレコード構成し、更に使用目的対応データ項目の相互関係分析をする。データ項目を関連づけたものをデータモデルといい、データモデル設計はDB設計基本作業そのもの。モデルの例として、階層モデル、ネットワークモデル、関係モデル、オブジェクト指向モデルがある。PC用DBソフトは、対応するデータモデルが予め決まるため、普通はデータ項目設計完了時点で使用ソフトウェアを選択する階層モデルデータを会社組織の様な階層的構造で整理したもの。構造は逆さにすると枝をはった木に見え、木構造とも呼ぶ。枝が交わらないよう、階層モデルも交わらない。レコードに親子関係を持たせるが、子は1親しか持てない。処理能力に優れるが、木構造より複雑な関係は表現できない
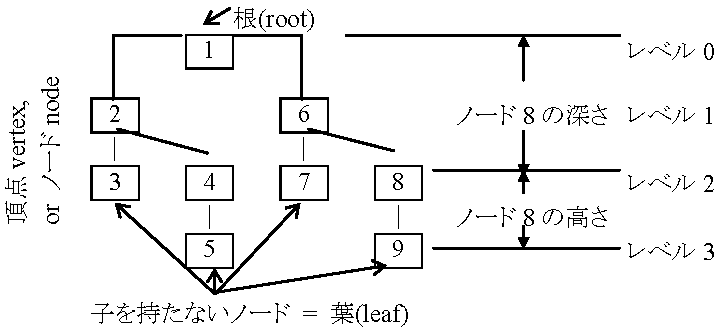
レベル1 ↓クラブ[クラブコート|クラブ名] 順序木: ノード間に順序がついている木のこと (子の順序は左優先としておく)
根: 入口のノード, ノード: 構成要素(葉): 子を持たないノード
a)各ノードの子は左の子又は右の子である ネットワークモデル階層モデル一般化モデルで、親が複数の子を持て、子も複数の親レコードを持て、関連網目構造をとる→ レコード間で親子を相互関連づける構造モデル [難点] データ構造複雑化 |
Q 模擬試験成績整理DBに必要なデータ項目は何か。複数大学情報や他高校情報を取り入れると、どのようなデータ構造モデルが考えられるか
学年 [学校コード|学校名] 図. ネットワーク型データモデルスキーマ。本モデルは、教員が学年とクラブに所属、生徒は学級とクラブに所属する関係を示し、子が親を2つ以上持つ 関係モデル(リレーショナルデータモデル)データを幾つかの2次元表の形に整理した単純構造で、行をレコード、列を項目とし、関係(リレーション)概念を導入しスキーマ定義する。このモデルの構成DBをリレーショナルデータベースと呼ぶ。2次元表を複数作成するのが普通である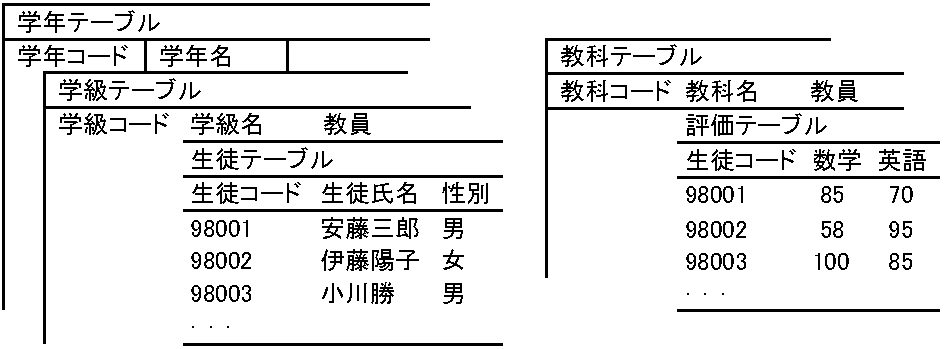 図. 関係データモデルのスキーマ例。生徒テーブルと評価テーブルを生徒コードで関係づける
コード: 指名: 性別: 数学: 英語 オブジェクトobject指向モデル現実に見えるもの(オブジェクト, O)同士の関係を直観的にコンピュータ上に表現する発想から生まれたが体系化遅れる。構造は分かりやすく、あるオブジェクトから別オブジェクトに作業を依頼し合う関係で示される。PC(OA)があり、製品番号・製品名・製造工場・利用者という属性値を持つ。属性表現で他モデルと違う点は、メソッドと呼ぶ操作手続きで一体化する。部品(OB)があり、部品名・部品番号・使用機種・製造工場等の属性値とそのメソッドが一体化しているとする。OA-B間ではメッセージを通し関連づけが行なわれるオブジェクト object: データ(構造)とプログラム(メソッド)の組み合わせ メソッド method: オブジェクトに付随する操作 クラス class: オブジェクトの持つデータや処理を規定するテンプレート Ex. 自動車エンジンというモノ(オブジェクト)に対し、その設計図や仕様書がクラス クラスライブラリ class library: 一連のクラス集合体で、ビジュアル開発ツールのソフト部品等に利用されるCORBA, Common Object Request Broker Archtiecture: OMGによるORB標準仕様 データベース検索データ検索: 指定内容と一致するものを見付け出すこと検索問題 → 情報記憶装置内格納法 + 情報抽出法 データが大きくなりデータと処理プログラムが分離されると計算式に合わせデータを準備するのは無理なため、データを作る側は個々の計算にとらわれずデータ表現し、データを使う側は多くのデータ中から必要部分を選び出し使うため、検索方法開発が必要となる。使う側は条件を与え検索する 単純条件: 問合わせ条件が1つ < 複合条件: 複数条件組合せ指定
1) あるデータと等しいものを探す Q 電車時刻表DBを作成したい。どのような検索をしたいか考えよ データ探索= ファイルから必要レコードを探す処理レコードのあるフィールドとその値を指定し、合致データやその格納場所を求める処理。Ex. 住所録からA市在住で17歳のレコードを探す 例題 大きさ順に整列されたデータファイルXがあり、その中にPというデータがあるか探したい ソート(並び替え) sort: データを一定規則に従い並べ替える処理。昇順: 小から大へ並べる ↔ 降順 昇順データがXの1 - n番目にX(1)、X(2), …, X(n)と格納される。X(1)から順にPと比較し同じものを探す方法を逐次探索(順探索)と呼ぶ。k番目データがPと同じならX(k)が探し当てたデータで、PがX(k)より大きくX(k +1)より小さいと検索失敗となる。大規模データでは効率化のためデータを2群に分けPが入る群を探し目標範囲を狭める二分探索法が作られた(図3.8)。n個のデータの内、中央データX(k)とPを比較し、より小さいと下方群を探索し、大きいと上方群を探索する手順を繰り返す。nが奇数ならk = (n + 1)/2であり、nが偶数ならk = n/2とする。X(k)がPと一致すれば探索成功だが、見つかる前に探索範囲がなくれば失敗となる Q データ列1, 5, 8, 13, 29, 38, 39, 43, 61, 78, 80, 92, 93, 99から二分検索でP = 50, 92を探索し探索回数を計る。 _________ ③ ←← ② →→ ③____ ①____ ③ ←← ② →→ ③ X(1)├────┼────┼────┼────┼────┼────┼────┼────┤X(n) __________________←←__ ←← X(k) →→__ →→ 図. 二分探索法 ①は始めにPと比較する位置で、その大小により次に探す位置を左右一方に決める。②③の数字は、何回目に比較する位置かを示す 文字列照合: 文字列中から、指定パターンを探す処理は、DBやワープロの探索でよく使われる 例題 n個の文字が並ぶテキストTXT[1 … n]中に、m個の文字が並ぶパターンPTN[1 … m]が含まれる時、その位置を探す。テキストに同パターンが複数ある場合には、最初に現れる位置を示すことにする
12 k k + m - 1 n Q 文字列 Projects and programs, programming language guideでprogramという文字列パターンを、スペースも1文字とし照合せよ。照合成功まで比較は何回行われたか データソート(並べ替え): 例題 9,15,3,53,6,21,30,60と並んだ数字を昇順に並べ替える 単純選択法: 1番小さい数字を選び1番目の位置の数字と入れ替え、次に2番目に小さい数字を選び2番目の位置の数字と入れ替え...を繰り返す バブルソート法: 隣り合うデータを順次比較し大小順序が逆転していれば位置を入れ替える 単純選択法
初めの状態 9 15 3 53 6 21 30 60
1 3 15 9 53 6 21 30 60
2 3 6 9 53 15 21 30 60
3 3 6 9 15 53 21 30 60
4 3 6 9 15 21 53 30 60
5 3 6 9 15 21 30 53 60
バブルソート
初めの状態 9 15 3 53 6 21 30 60
1回目パス 9 3 15 53 6 21 30 60
9 3 15 6 53 21 30 60
9 3 15 6 21 53 30 60
9 3 15 6 21 [30] 53 60
2回目パス 3 9 15 6 21 30 53 60
3 9 [ 6] 15 21 30 53 60
3回目パス 3 [ 6] 9 15 21 30 53 60
4回目パスは入れ替えがないので整列終了 配列 array: メモリ内に順次に並べその位置をとったデータの入れ場所Basic, C: 0から始まる / Fortran, Cobol: 1から始まる マトリックス matrix: for文の繰り返しで表現可能
遷移過程: 1つの状態が他の幾つもの状態に移って行く過程 スタック構造はデータの保存と読み取り速度を決める キュー queue: 発生データが、ある処理を受けるため並んで待っている状態を表現するデータ構造。新しいデータは列の一番後ろに並び処理は列の前より順に行われる – データは常に隙間なく連続して保存→ 問題: データの途中追加削除の際、データ移動の必要があり時間がかかる。エラー時に復元難しい リンクドリスト (linked) list: キューにおいて安全かつ素早くデータ追加、削除を行うため考案された。データ内容の1項目に次データの番地(ポインタ) pointer情報をもつ形式方法1: テーブルを使う場合
Start (List head) → Data 1:Pointer → Data 2: Pointer → Data 3: Pointer → Data 4: End 方法2: システムで番地管理を行う場合 → Pascal, C等の言語ではメモリサイズ指定できるため可能 データがディスク上にあるとき – 少ないアクセスで検索を済ませることが早い処理を行うため必要対応表(デンスインデックス) dense index: データキーとそのディスクに書かれた対応表を作り、ソートした形で保管 スパースインデックス sparse index: データソートしディスクに順次書き、単位page毎に区切る。ページ毎の最初のデータキーを集めキーとページの表を作ったもの。検索キー投与時、インデックスを読み込み番地を探す。スパースインデックスはデータが増加時にインデックス付け直しが必要で、データ変化が起こらないほどよい ハッシング hashing: データキーを数値化し、その数値とデータストア番地を対応させること
key → p = H (key) → ハッシュ関数 → 番地pにkeyのデータを書く |
W³プレゼンテーション計画プレゼン(テーション) presentation: 情報発信者が公開する1まとまりの情報 → 「実演・発表・説明」の意味もあり「W³プレゼンテーション, W³ページ, Webページ」と普通言う= ブラウザ画面に表示されるWebページと呼ぶ単位の1つ以上集まり → Webページ同士はリンクし行き来 W³での情報発信への道のり「ページを作り公開する」までの内容
(4), (6)が難しく重要に思えがちだが、実際はその他の部分も等しく重要 ウェブマスター WebMaster: 企業のW³サイトの開発・管理を行う職業。仕事内容は、全社的インターネット戦略の立案、各部門との共同作業によるコンテンツ作成、サーバ・ネットワーク保守、HTMLコーディングや、コンテンツデザイン、サイトに寄せられる電子メールの対応、Internet新技術の調査/評価等、多岐に渡るプレゼン着手前に、(1)目的、(2)含める情報範囲、の2点は明瞭にさせておく。これらが曖昧なままプレゼン作成しても、「何となく作った」に終わり役立たない。目的は、明快に一言で言い表せるべきで、「W³ページ作成を練習する」でもよい。W³は他人に何かを伝える手段であるから、「これこれのを伝える」という目的の方がよいプレゼン(他の人から見て面白いプレゼン)になり易い。プレゼンに含まれる情報範囲を決めておかないと、プレゼンが何%位完成したか、まだ何が足りないのか等が分からず、情報構成を決めるのもうまく行かない 例題
目的 = 「なぜコンピュータについて学ぶのか?」を自分達が考えたことを多くの人に知ってもらう 良いWebページを見つる: 見易く分かり易いページ = 「良いWebページ」 → 良い所を学ぶことが大切 扉ページ: W³情報発信時に最初訪れてもらう扉ページは、一目で中身の検討がつき読む気にさせるよう工夫し書かれる。しかし、グラフィックに凝った結果、ページ閲覧に時間がかると遅い回線使用者は事実上読めない。扉ページは「早く、分かりやすく」という条件が求められる 文書分散: W³は、HTML文書の分割により見え方が違う。不必要に分割し幾つもリンクを辿る文書は読むのが面倒で、構成が出鱈目だと読むのを諦めるかも知れない。3回程度で最終的文書に辿り着けるリンク構成を考えるべき。プレゼン作成に、ページ間の繋がり方は表現を相手に効率よく伝えるため重要となる
線形構造__↔ ■ ↔ ■ ↔ ■ ↔ ■ ↔
線形構造: ページが最初、次、その次、と直線的にリンクで繋がり順番に並んだ構造 例題 構造 → 入口ページ = 目的、科目構成、教科内容、議論: 教科別にページ → 入口ページからリンク Q テーマを1つ選び、検索サービスを利用し、そのテーマを取り上げているW³プレゼンを複数探し比較せよ。どのように違っているか。各々のよい点、悪い点は何か。表の形にまとめよプレゼン全体構成決まれば、各ページ構成に進むが、プレゼンページスタイル(見え方)を決めておくことが肝要である。1プレゼン内で各ページが共通スタイルを持つと、読み手は「続いたプレゼンを見ている」と安心でき、複数人で分担しページ作成しても散漫な印象にならず済む 例題
例題: ページスタイル - 各ページ構成 ページに含まれる項目(必要なだけ繰り返す)
区切り線 |
例題: 入口ページ構成
表紙相当部分: Webページデザイン時、冒頭部は表題に示した内容の視認性を高め掲示するのが一般的で、画像挿入も多い 中身: 普通の文書が表示されるよう書けばよい 奥付: 本では、著者(略歴)、出版社、印刷所 ・出版年月日、印刷年月日、版数、刷数、著作権表示、定価、ISBNコード等「出版業的情報」を書く部分 → 書店・図書館等は奥付から本を整理し、読者は奥付から著者を知る。本の引用、紹介時も奥付内容が正式情報となるのが通例で、奥付は「本の権利を守る部分」である。W3発信情報は、情報作成者・情報発信者が様々な権利を有し、その権利の存在と権利保有者を明示し、権利侵害を防ぐ効果を期待しWebページにも奥付をつけるべき。Webページ奥付では、「著者名・制作者名・制作年月日、改訂年月日」「著作権表示(著作権者の表示)・正式URLとURL公開の可否」「連絡先(メールアドレス)」の表示がよい 情報ネットワークとコミュニケーションテーマ分割: 1つのEメール・ネットニュース記事に複数テーマ出てきた場合、内容散漫にならぬようテーマ分割し、複数のEメール・記事として反応することも、場合により議論の流れをよくする有効手段となる。この場合、分割テーマについての反応であることを示すために表題を書き直すべきW³の特徴と弱点特徴: ハイパーテキスト構造 (W³最大の特徴) → 活用すべき
W³は「誰もが有用情報を得られる」ようにした功労者であり、インターネットブームのきっかけとなった プレゼンテーション公開・検査・保守ページW³公開: ファイルをW³サーバ上に置く(転送方法やファイル保管場所はコンピュータ環境で違う)
使用ホストがW³サーバ、W³サーバディスクをネットワーク経由で自分のマシンから入出力できる環境 「表示できる」 ≠ 「プレゼン完成」 → プレゼンは世界中の人が見る。プレゼン向上に1分掛ければ多数の人の1分を節約と思うべき。具体的に次の点をチェック
タグ使用法がHTML規則通りか。開始終了タグが対か、タグ名や属性のスペルミスないか、等
複数ブラウザで、プレゼンが問題なく見られるか、使いにくい所はないか ルック・アンド・フィール look and feel: 見た目と感じ → HP公開で大事な点の1つ 文献
|
2017年5月8日現在
|
 1 1
 2 2
 3 3
 4 4
 5 5
 6 6
|
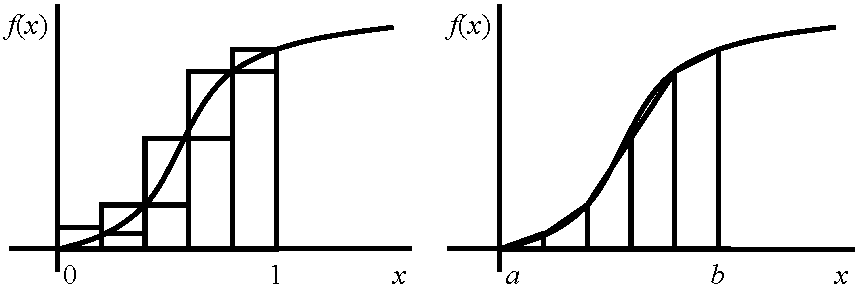
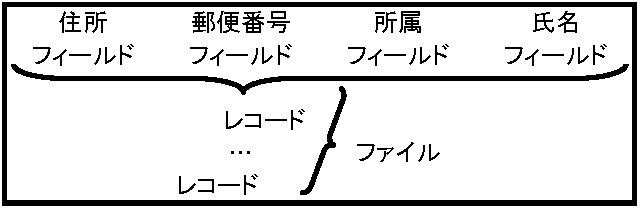 ファイル構造
ファイル構造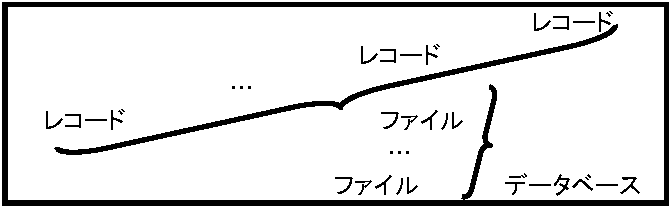 データベース構造
データベース構造