(2026年3月7日更新) [ 日本語 | English ]
HOME > 講義・実習・演習一覧 / 研究概要 > 小辞典 > 情報科学
|
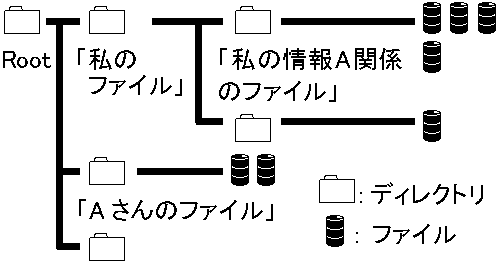
情報社会: 多量の情報中から自分に価値ある情報を見つける必要 情報拡大 → 選択肢広げる = 情報を主体的に得る自己責任 電算機発達で情報収集・貯蔵・引出能力大変化 → 情報取扱い方が大課題 Def. モノobject: 個々の外部に存在する物体や生物 Ex. 動物: モノを感覚器官で受け取り、脳で処理し、行動 「情報」と「データ」は曖昧に使われるが、誤解ない議論のため定義必要 → モノのうち、人間が判断や評価づけする素材や資料をデータ、データに従い判断や行動に役立つものを情報とする Def. データ data: 判断評価を下す元素材 → 文字列や数値の形で形式的に表現された事象や概念Def. 情報 information: 特定状況で判断評価できる資料 → データが現す内容で事実に基づく意味を持つ Ex. 天気予報: 夏の全国高校野球夏大会中 → 兵庫県南部、一日中晴天、最高気温32°C、最低気温25°C
→ 球場弁当売りには、明日用意する弁当数判断に必要な「情報」 コンピュータ: 自己価値判断できずネットワーク(NW)上のものは全てデータ → 人により「情報」となり「データ」となる 「データ」が、状況変化と共に「情報」に変化することもある 情報自体 = 無形 → 外に現れた情報は計量可能 → 価値valueは人が決定Ex. 戦国武将 「空腹か」より「敵が来たか」「Yes/No」情報が遥かに重要 判断評価 → 知識利用: 情報は「判断材料」というニュアンスがあり、天気図から「気圧配置異常! 冷夏?」と考えると、天気図データを情報とし判断を下す「何か」を持つ → 知識知識蓄積目的は、問題解決のためであり試験のためではなく、「辞書の様に詰め込んだ知識」は具体的諸問題への対処力低く「死んだ知識」となる Def. 知識 knowledge: 情報やデータを体系的にまとめ、判断や思考に利用活用できるように蓄積されたもの ガーベージ garbage: 記憶装置上の意味をなさないデータ。つまりゴミ GIGO: 信頼できないデータから得た結果は信頼できない
Ex. 必要以上の食物を入力し大量の汚物を出力 |
情報社会パーソナルコンピュータ (パソコン personal computer, PC)普及: コンピュータ(組込機器)発明が情報社会出発点初期: スタンドアロン(単体)使用 = データ処理・結果出力 = 科学技術計算・事務処理合理化 → × 情報社会 現在: コンピュータ + 通信NW digital communication network 技術 → 社会形態変化 コンピュータデータ通信網 → データをリアルタイム取得でき、情報量も格段に増加 → 情報システム: [基礎技術 = NW、データベース(DB)] + [応用技術 = 音声認識合成、筆跡認識、曖昧情報推論等] → ヒューマンインタフェース human interface 高度化: 使い易いものに変化+ マルチメディアデータソフトウェアによりPCは身近となる 情報(化)社会 information society: コンピュータ同士を結ぶデータ通信網により形成された社会(といえる) ☛ 情報倫理情報化加速 → 「情報社会」(1960年代末日本で使用) = 社会変化よく表し世界中で使用 新技術普及 → 社会変化 → 個々人の技術的機構・使用方法習熟だけでなく、用いた行為が人間・社会に及ぼす影響を理解し制御する必要 = 情報化進展が人間関係・企業活動に与える変化を知る 環境問題を考える場合同様、出来事を、流行を追うように見ても問題の本質は捕らえられない 高度情報(化)社会: コンピュータと通信の有機的結合が広く行き渡った社会情報処理 = コンピュータ ↔ (協力) ↔ 情報伝送 = 通信機器 → NW DX (デジタルトランスフォーメーション, digital transformation)情報技術(IT)を浸透させることで人々の生活をより良いものへと変革すること |
[画像解析]
情報表現するモノ(メディア media)の種類・特徴を、情報科学の視点から整理する。コンピュータによる問題解決やネット交流では電子的表現情報が活躍し、情報社会はコンピュータと電気通信NWにより支えられた社会といえる。飛び交う多種多様な情報は、コンピュータや電気通信 tele-communication に相応しい形で表現される。この表現は、2記号組合せで全情報を取扱う(2進)デジタル信号(= デジタル)と呼ばれる。デジタル信号の意味を理解し、文章・数値・画像・音等多様な表現と原理を知る。コンピュータ出現以前の情報表現を振返り、そこに見られる工夫と人間の認知能力との関わりを知る。人間とコンピュータが情報をやり取りする時の窓口(マン・マシン・インターフェイス man-machine-interface)のあり方を考える基礎にも触れる記号の発明とその処理 (☛ 記号論理)情報を取扱う頭脳の働き面から人間の特徴を見る。生物行動の殆どは遺伝子情報に支配されるが、俗に言う高等動物ほど誕生後の学習が重要になる。学習は、動物の生活環境に存在する「モノ」との関係を通し行なわれ、その経験が知識として蓄積される。「モノ」は、無機質な物質や動植物、そして人間まであらゆるものを指す。人類は、情報を記録伝達する人工的「モノ」を発明し、情報を記録伝達する「モノ」を“記号symbol”と呼ぶ。記号発明はとりもなおさず「書く」の発明といえる。「書く」は恐らく絵のような具体的表現の「描く」から始まり、やがて象徴化や図形化を経て、言葉を「書く」文字へと進歩を進めた
Ex. 見かけ・匂い → 今まで食べた物の記憶 → 食べるのを止める 文明文化: 食料や生活材といった「モノ」自体の生産はもとより「記号」活用による情報伝達とにより作られる アルファベット「記号」、またはその単語・文法知らない人は、アルファベット情報は、価値ある内容でも情報活用できない。「記号」が価値を持つには、扱う者に解釈可能な形で表現される必要がある。情報社会では、コンピュータデータ処理し処理結果を情報利用する。コンピュータは電気的に動き、コンピュータ情報処理は情報やデータが電気的に取り扱えるよう表現されねばならない。この表現は、人が慣れ親しんだ表現と随分異なるが、生じる技術上の問題は、文字・数字という「記号」を取り扱う際に経験した点と通じる。情報社会の本質を学ぶことは、何気なく使う文字・数字という「記号」の本質を問い直すDef. 記号, s.s.: 人工的に発明された文字・数字等 ⇔ (s.l.) 遺伝子、神経伝達物質、羽模様等、情報伝達に関係する全現象を情報研究成果から考える。逆に、脳や動物コミュニケーション研究が、新原理コンピュータや情報NW研究に影響し、情報研究は幅広い学問分野と関わり進む 実体としての「モノ」と抽象体としての「記号」Ex. 「古池や 蛙飛び込む 水の音」(芭蕉) → 俳句の価値1) 価値 = 「言葉(字句)の意味」 → 口伝、手書、活字印刷本、価値は同じ 意味の情報価値は、表現媒体(メディア)によらず、複製でき読めればよい 2) 価値 Ex. 芭蕉直筆の短冊(実体)
言葉の価値 + 文字形、文字配列など視覚的効果(芸術的骨董的価値) 偽物(贋作)は、本物の持つ実体価値の多くを失う → 劣化: 短冊という実体は、作られた瞬間から劣化が始まり価値が変化する 絵画・彫刻では、言語芸術と比べ、芸術価値は、形作る「モノ」という実体そのものが価値の正体となる。音楽では、作曲家は作品を楽譜にし、残された音符記号は、演奏家にとり作曲家の産み出した情報としての価値を持つが、聴衆には音楽価値は演奏で演奏が終わると音楽も消える。音楽にとって、楽器は芸術的価値を生み出す「モノ」だが、楽器は音楽そのものでなく、空気振動という「モノの状態」が音楽価値となるこれまでの文明や文化では、「記号」、「モノ」、「モノの状態」の差違が比較的明確であった。しかし、情報革命の進展に伴うデジタル表現された情報社会では、このような見方を超えた新しい表現世界を切り開きつつある 情報表現からみた記号の本質 -文字と数字を振り返る-コンピュータ内部では、コンピュータ特性に合う電気状態で情報表現されるが、入力データや処理結果出力部分は、普段見慣れた文字数字出力され、内部の文字数値処理形態は意識されない。コンピュータで誤りなく計算・通信するには、内部文字数値表現の理解が必要である。コンピュータで画像や音の処理方法を理解する基礎でもあるQ 身近な物を、それがもつ情報に意味がある、そうでない、どちらともいえないに分類し、結果を人と比較せよ Q 1) コンピュータ発明につながる計算道具の歴史、2) 主流コンピュータ以外の研究、を調べよ 文字の発明と進化 -表意文字、表音文字-本来文字は、「モノ」、「モノの状態」、「モノの関係」記録に事柄を1対1対応で作られた。最初の文字は、記録事項をを図式化した象形文字で、名詞のみならず、動詞、形容詞等、言葉になるもの全て図式化が図られた。文明文化発展し、表現事柄が増え事柄毎に対応し文字を作ると人の記憶能力を越える ⇒2種類の問題解決方法: (1) 表意文字: 複数記号組合わせ文字数減らす。字形抽象化進み、形の由来不明や複数の意味を持つ文字も現れたが、「形 = 意味」の本質的特性変わらない Ex. 漢字の偏と旁
利点: 形で事柄を表現でき、少ない文字数(時に1つ)で豊富な内容を表現 (2) 表音文字: 文字を要素とし、その組合わせに意味 (文字自体は具体的意味ない) Ex. アルファベット、平仮名
利点: 少数の活字で済む - タイプライターが発明され日常生活に普及
メモ 昔のコンピュータで「印刷」は、"copy"命令をキーボード入力した。今は、画面上"copy"アイコンiconを押し実施でき、象形文字への先祖返りとも言える。キーボードからc,o,p,yと順に入力しコンピュータに印刷処理させる場合も、コンピュータ内部では"copy"文字列が対応命令コードに変換され、そのコードをコンピュータ頭脳部分(CPU)に送られ処理される コンピュータの文字利用も同じ。コンピュータでの文字処理には、コンピュータ内部に予め利用する文字と1対1に対応したコードをメモリに準備(記憶)しておく必要がある。コンピュータで漢字利用するにはアルファベットに比べ膨大なメモリが必要になる。メモリは、技術革新によって安価になったが、メモリは高価な時代は、コンピュータでの漢字利用は、アルファベット利用に比べ遅れ、当初はよく使われる一部の文字(日本語ではカタカナ)だけが使われた 数字と記数法、数値表現の発見と進化数値を表わす記数法も文字同様、記録から始まる。大昔は、取り扱う数値も小さな正整数に過ぎず、記録したい整数値分だけ点や線を書き並べた。しかし、人間が瞬時に個数を識別できる能力は意外に少なく4-5個程度なため、点や線の配置を工夫したり(Ex. トランプ)、5とか10の固まり毎に新しい記号を作る工夫がなされた。この段階での記数法は象形文字同様、単に表わしたい数値と数字を1対1に対応させるものだった (→ 「基本数字」)
束の考え方と非位取り記数法整数が大きくなると工夫がなされた。「10個の束」を作り、その束に「10の位用記号」を作り、更にその束が10個集まった「100個の束」に「100の位用記号」を作り...と各位に対応した「位数字」が発明され、それらを必要な個数だけ書く方法が取られた685を「百百百百百百十十十十十十十十五」と書く方法で、具体的個数との対応が見え易く加法は容易なことから長い間利用され、1位の「基本数字」とその個数を掛算表現する、今日の漢数字型記数法が発明された。「必要な数字の個数を掛算し簡潔に数値表現する」発想は、「情報圧縮」の原点といえる 「百百百百百百十十十十十十十十五」 → 六百八十五 この方法でも数値大きくなるに従い、新「位数字」追加の必要がある欠点残る Q 漢数字の位数字を調べ、漢数字で表現できる最大数値を書き表せ 数値と数字: コンピュータ内部で、数字は文字とし扱い、計算数値では文字と異なる扱いをする。「数値」と「文字としての数字」の違いを認識せよ ゼロ(0)の発見と位取り記数法0(零)のインドでの発見は、他数字に遅れ、0, 1-9の10基本数字を位に応じた位置に置き任意数値を表現する位取り数法発見は遅れた。数字に限らず、文字は本来「存在するモノや事柄に対応し記号を作り記録」するため発明され、殆どの文明圏で「何もない」状態を記録する数字、0がなかった。位取り記数法は、アラビア文化圏を通じ欧州にもたらされ金利計算に便利なため商業活動の広がりと共に普及し、筆算技術改良と結びつき近代科学発展に貢献をし、算用数字と呼ばれる。任意数値を、10個の限られた数字配列で表現する位取り記数法の考え方は、アルファベット組合せで任意単語を表わす表音文字といえ、位取り記数法には表音文字と同様の利点欠点が存在する。500003062を一目で「五億三千六十二」と読むのは難しい記数法と計算数字発明時の数字機能は記録目的で、計算(筆算)機能は重要視されなかった。計算の工夫は、むしろ計算補助道具(算盤、計算尺等)にあった。電卓や表計算ソフトという計算道具(機)で計算し結果を利用する、道具力を借りて計算し結果を記録するやり方は現代社会の特徴ではない。算用数字の十進位取記数法が普及した最大要因は、簡単に計算できる(筆算)ことといえる。十個の数字で殆どの数を表わせ、自然科学研究で欠かせない記数法になった。算用数字による十進位取り記数法普及は、数値記録の歴史では最近であるメモ 算用数字普及以前は、現在奇妙に見える指を操る計算方法とか、計算結果を予め示した表利用等の計算手順(アルゴリズム)が多数考えられた メモ 算用数字は字形単純で、位取り記数法では数字追加し数値を書きかえられ、算用数字の手書き十進位取り記数法は偽造がある。アラビア文化圏から欧州に算用数字がもたらされた当時、偽造がはやり「算用数字使用禁止令」が出た。今日でも大事な記録では漢数字で壱、弐、参と書くことがある Q 1) 漢数字を使い計算、掛算や割算をせよ。2) 計算の歴史を計算手順(アルゴリズム)に着目し調べよ 二進デジタル表現への道 -情報社会を支える情報表現-コンピュータは、文字や数字、数値、更に音・映像等全データを「電流が流れる・流れない」「磁気がN極かS極か」という単純な電磁気現象の2状態変化を利用し情報処理する。正確には、データが2状態の組合せにより表現・記憶され、データ加工・計算指示(命令)も2つの電磁気現象の組合せで行なわれる。自然は無数の色や音に満ち、普段扱う文字やそれを組合わせた言葉にも多数の種類がある。数値は理論的には無限に存在し、数値修理には複雑な計算を伴うものもあるが、全て単純な2つの電磁気現象で扱える文字や数字の個数を決めるもの扱う文字種類は、英文では、26個(大小52)のアルファベットと.や?、!等幾つかの記号で出来ている。算用数字は0を含め10個である。日本語は、何万のもの漢字が使われる。しかし、文章記録や数値処理には、26個や10個である必要はない。今ある記号数を決めたのは、人間の記憶能力や五感に関係し、コンピュータ情報処理では、日常利用する文字個数とは無関係に考えられる文字記号を増やした世界アルファベット27番目としてθ記号追加し、頻出するthに当てはめると、英単語は簡潔に表現できる Ex. this → θis, there → θere, three → θree数も9の次にABという数字追加し、12で繰上がる12進法を位取り基準にした表記できる
(十進法) 8 9 10 11 12 13 → 8 9 A B 10 11 (12進法)
Ex. 数の読み方 文字記号を減らした世界Rule [文字・数字数を減らす] → Ex. 英字アルファベットからz省略 → zを含む単語は残りのアルファベット組合わせ(Ex. aa)に置き換える。その新単語が既存単語になければ、それを新単語表現と決めるzoo(動物園) → aaoo, zero(零) → aaero, fuzzy(曖昧) → fuaaaay 実際に26文字より少ないアルファベット系言語もある。数値では、0, 1, 2, 3の4字だけを用い4になると繰り上がる4進法にすると、次の表記が考えられる(十進法) 2 3 4 5 6 → 2 3 10 11 12 (四進法) 情報表現に必要な最小記号数情報表現記号数を減らせる下限を記号1から検討する。表現したい文字がN個なら、基本記号を1つ用意し、1個なら1番目の文字、2個 = 2番目 …, N個 = N番目と対応させる。今基本記号を「ピ」という1秒間の音とし、以下2秒間のピ … N秒間のピという長さの異なるピと文字を対応させる
- → 水, -- → 島, --- → 男 分離記号による解決個々の文字を他文字と分離する記号を導入し、それを「ポ」とし•で表わす。すると、abは「-•--」と表現できる。英語はアルファベット組合せで単語を作る表音文字のため各単語を「分かち書」し識別する。文章を、「bc a abc」とする。ポ(•)を使えば単語と単語の分離(分かち書)には空白(スペース)に対応する第三記号パ(*)を使えば「--•---*-*-•--•--」となる。しかし、個々の文字の区別区切りはポ(•)を1つ、単語の区切りにはポを2つ並べるから「bc a abb」は「--•---••-••-•--•--」と2記号で表現できるメモ 英文単語間空白(スペース)は「紙面の地肌」だが、情報表現では空白は単語を区切り文章作成時の分離記号(文字)である。アルファベット系文章も、表音文字のみでなく、空白や終止符(.)、疑問符(?)等は表意文字である Q アルファベットの-表現と、区切規則(•及び••)用い、This is a penを表現せよ Q aに1個の-、bに2個の--と対応させるアルファベット表現方法は、文書作成時の手間や保存、伝達の際に経済効率が悪い。理由を考えよ。(Hint: 出現頻度、モールス信号の工夫) 一定個数の記号の並べ方パターンによる解決N個の場所を用意し、その場所に-と•のどちらかを置く場合、何パターン出来るか。場所が1つの時と•の2通り / 場所が2つの時と-•と•-と••の4通り / 場所が3つの時と--•と-•-と-••と•--と•-•と••-と•••の8通り → 一般に、場所がN個あると、-と•を使うパターンは2N通り出来る。次に、N個数の場所に置いた場所-と•を置くことで出来る2N個の異なったパターンに各種のアルファベットや数字、ピリオド(.)やク疑問符(?)、+、-、空白等といった特殊記号を対応させ割り当てを考えた時、Nを幾つにすべきか。アルファベット小文字大文字は52個、数字は10個、これに特殊記号を含め、通常の英文は100種類程のパターンが必要となる。100種類程度のパターンに必要となるNの値は、2N > 100となる最小のNの整数解を求めればよく、答えは7で可能なパターン総数は128個であるQ 場所がN個あると、-と•を使ったパターンは2N通り出来ることを証明せよ Q -- -- -- -をパターン最初、••••••を最後とし、128個全パターンを書き漏れなく工夫して書け 128パターン個々にアルファベットや空白等の特殊記号を対応させ任意文章を書ける。読取る時は先頭から7づつ区切り読むので個々のパターンを空白で区切る必要なく、一定個数Nの場所においた-と•でのパターン表現方法は、各文字パターン長(-と•をおく場所の個数)が一定なため固定長表現という。固定長表現された文章中の-と•の総数は「文字数 × N」で求まる。一方、分離記号を利用した表現方法は、文字により与える記号数が異なり-と•の総数は「文字数 × N」で求まらない。一連の情報の切れ目を分離記号で行う方法を可変長という。固定長・可変長様式は、コンピュータ利用の随所で見られる ビット列と2進数答がYes/Noのような「二者択一」情報は、これ以上分割できない情報最小単位と考えられ、この最小単位をビットbit (b)と呼び、情報科学では情報量を計る最少単位となっている。記号化可能情報は、ビット(b)を使い表現できた。簡潔に書き表すため、1bを2進法 binary systemの1つの桁に対応させ0/1で表す。こうしておけば、複数ビット組合せも見やすく表せる。雨の降りかたをもう少し細かく表したとする。そのため、2bを使い
降り方 降ってない 小雨 本降り 土砂降り Def. ビット bit: 「2つの内どちらか(異なる状態)」を表わす情報最小単位。「2進法1桁」binary digitの意味 Q 情報で、「2つのうちどちらか」「N通りのうちどれか」で表せるものを考えよ メモ 情報科学で「情報量」とは「情報に何ビット必要か」という意味で、情報価値の大きさではない。「論論み花花」と「明日は休校」は共に5文字で、情報科学的には「同情報量」ですが、情報の「価値の大きさ」は違う ビットによるまとめ
コンピュータ内部での情報取り扱い符号化(コード化): 様々な情報をビット列に対応させ表すこと符号化規則: 符号化の対応づけ規則 Ex. 「雨が降っていない」 = 0、「雨が降っている」 = 1 文字数値をビットパターンに対応させる際、規則のある形で作ったビットパターンに通し番号(順序数)をつけ、次にその番号順に文字や数字を対応させると、数値処理でき便利なので、コンピュータでは、-と•といった記号ではなく0, 1だけで数値を現せる2進位取り記数法(2進法)を基にビットが扱われる。「電流オン・オフ」、「0 Vと5 V」、「磁石N極, S極」といった2種類の電磁気現象で0, 1を扱う。代表的情報の種類毎に符号化を見る。(ただし、デジタル情報送受信両者が同じ符号化規則を使わないと正確に情報が伝わらない。情報種類毎に標準符号化規則を定め、共通に使うのが一般的)二進法の原理十進法位取記数法(十進法)での256の意味は(256)十 = 2·102 + 5·101 + 6·100である。一般に、n進法でf桁の数値(abcde)nを巾乗表現は、次になる(abcde)n = a·n4+ b·n3 + c·n2 + d·n1 + e·n0 … (1) abcdeを仮数、nを基数という。仮数は、n種類の数字で、その内1つは0(ゼロ)でなければならないQ 2進法の100111011110を10進法で書け。(1)でnを2とし計算 (Q 2526) Q 10進数の536を二進数にするには、536を2で割った余りを並べていけばできる。これを証明せよ 53 = (26 × 2 + 1↑), 26 = 13 × 2 + 0↑, 13 = 6 × 2 + 1↑, 6 = 3 × 2 + 0↑, 3 = 1 × 2 + 1↑, 1 = 1↑ → (110101)二 → 2進10進変換 (110101)二 = 1 × 25 + 1 × 24 + 0 × 23 + 1 × 22+ 0 × 21 + 1 × 20 = 32 + 16 + 0 + 4 + 0 + 1 = 53 (答)(110101)二 → 2進10進変換 Q 2進法から十進法への変換や、bの十進法から2進法への変換方法は、「十進法を基準とする立場の変換」。「2進法を基準とする立場」だと変換方法も変わる。「2進法を基準とする立場」での変換方法を考えよ。(ヒント: 計算は十進の「九九」や加減が基準である。「2進法を基準とする立場」だから、「九九」は「二二」に、加減も2進法規則で行う) A = アルゴリズムが逆転する 二進法と16進法使う数字の少ない2進数は、十進数に比べ同数値の表現に桁が長くなり、記載には不便で読み間違いも起こり易くなるため、コンピュータや通信関係では二進法そのものではなく、16進法(か8進法)が使われる。16進法が使われるのは、2進法と16進法の変換方法が2進法と十進法の変換に比べ容易だからである。16進法は16個数字が必要で0-9は算用数字を10以上はA-Fを当てる
漢字__零__一__二__三__四__五__六__七_ 八_ 九__ 十 十一 十二 十三.十四.十五 二進数と16進数との相互変換Ex. 10011100110
メモ ビットによる情報表現の考え方自体には16進法は必ずしも必要ではない Q 証明せよ(16 = 24): 1·26 + 0·25 + 1·24 + 1·23 + 0·22 + 1·21 + 1·20 = (1·22 + 0·21 + 1·20)·24 + 1·23 + 0·22 + 1·21 + 1·20 パリティ(偶奇性parity)・チェック電子回路は精度高く作られるが、ビットパターン伝送途中等で特定ビットが1から0に置き換わることがある。処理ビットパターンの正確さを調べるため、本来の文字ビットパターンにチェック用ビットを追加し情報表現に余裕(冗長性)を持たせる方法が生まれた。簡単なのがパリティ・チェック parity checkで、元データ先頭に1bのパリティ・ビットを追加し、データビットパターンにある1の個数が偶数なら0、奇数なら1としデータを扱う。ASCIIでは、「パリティ・ビット1b + 文字コード7b」の計8bを単位とし文字コード伝送し、受信側は、文字部分の1の偶奇を調べパリティ・ビットと一致すれば「誤っていない」、不一致なら「誤っている」と判断する
… 11000011 11000010 … < 信号が来た。> < パリティチェックしよう > 符号化 (半角カタカナ)初期コンピュータ = 処理スピード遅くメモリ高価 → 日常漢字使用困難アルファベット同様7bで扱うカタカナと日本語特有の「、」、「。」という記号のみ利用 = 「半角カタカナ」 → 今日使う全角漢字 = 16b表現: 半角カタカナと全角カタカナは、形は似ても符号化上は別で混在は問題2つの半角カタカナ表現法: JIS7ビットコード vs JIS8ビットコード(1) 分離記号を使いASCIIの2-7列目ビットパターンに、(41)十六はAと半角チというように、同じビットパターンにアルファベット系とカタカナ系の2つの記号を割り当てる。そしてアルファベット系とカタカナ系の判別は、ASCIIの0列と1列に割り当てた機能コードの(0F)十六のSIと(0E)十六のSOで挟まれたものをカタカナ系、挟まれていないとアルファベット系とする
Ex. ABチツABの表現: (41)等は16進法表現 Q JIS7ビットとJIS8ビットのコード表で片仮名等の割り付け方を調べよ 符号化 (全角漢字) JIS第1水準と第2水準の実際コンピュータ高機能低価格化進むと漢字(日本文字)利用要求が高まったが、漢字符号化は、多数の文字記号があり簡単ではない。日本だけで、歴史的には何万個になるが、大多数は日常生活で殆ど使われず、全漢字を符号化しコンピュータに乗せるのは実用的にも費用面からも得策ではないこの作業には、漢字選別作業と、選別漢字の符号化割り振りという、2つの解決すべき問題がある。漢字には音読み訓読み等複数の読み方を持ち、アルファベットのように単純ではない。このようなことを考え最初に作られたコード体系がJIS第一水準漢字群で、以降も幾つかの漢字が追加されている。漢字追加では、既に社会普及した文字とビット列との対応関係の調整という問題も起こる。従来使われた漢字コードを追加する漢字で利用し、元漢字を別コードに移し変えたりすると、混乱が起こる。日本語処理は16b = 2B (65536ビットパターン)で漢字、(カタ)仮名、アルファベットや各種記号を扱かう。16bで符号化された漢字を7bや8bの半角のアルファベットと区別し全角漢字と呼ぶ。漢字取扱規格で良く使うものに「JISコード(ISO-2022準拠)/シフトJISコード/日本語EUCコード」があり、JIS指定漢字数は6353字である 通信MW普及に従い漢字をより統一的に取り扱う規格としてISOは書類番号10646で新文字コードを定義し、XeroxとAppleが中心に開発した16bit文字コード体系ユニコード Unicodeという新文字コードが作られた。欧米、日本、中国、韓国を含めた主要文字種が混在できる。今後、普及すると考えられるが2 byte目に1 byteの制御文字と同じコードが入ることや、JISコードと並び順が全く異なる、外字領域少ない等から、反対もあった Q 各種漢字コードの符号化規則を調べ比較せよ Q DBや表計算ソフトで漢字人名を「あいうえお順」ソートしても並ばないことがある。漢字コード表から理由を考えよ。「あいうえお」順に並べる方法も考えよ テキストファイルとバイナリファイルワープロメーカーが顧客アンケート調査 → 「黒以外の色や異なる大きさの文字が使えるワープロが欲しい」。メーカーA, Bは次のように考えたA社の対応(まず文字色を増やすことに重点をおき改良) A社のワープロでの文字の扱い → 色指定に4ビット+ASCII8ビット 「拡張ASCII8ビット文字コード先頭に4ビット追加した12ビットで1文字扱う。先頭4bで出来るパターンは16種 = 16色使える。0000は黒、0101は赤だ」
Ex. 赤色A黒色B 0000 01000001 0101 01000010 B社のワープロでの文字の扱い サイズ2ビット + ASCII+色2ビット Q A社ワープロソフトで黒A赤Bという文字をB社ワープロで読むとどうなるか。(ヒント) ビット列 0000 01000001 0101 01000010 を 00 00010000 01 01 01010000 10 と切り直しB社の規則で読み直す要点は、各ビット列対応文字属性や文字飾が、ソフト開発メーカー独自性に左右される点である。ビット列を切分け、具体的文章表現とし実現させるのがワープロプログラムである。ワープロ文書形式がメーカー毎で異なり、そのメーカーのワープロソフトでしか正しく読めない点はユーザに不満だが、メーカーを縛る規格が少ないことは技術競争を進める利点もある。最近は、他社ワープロ作成ファイルのファイル変換プログラムを用意し、できるだけ同じ文書イメージで読めるようにし、他社メーカーワープロ使用ユーザを自社ワープロユーザにしたい競争原理が生出した結果だが、ユーザにはワープロを変えても既存文章を再利用できる効能を生む 文字化け原因
|
文字化けと別問題だが、添付ファイルは作成ソフトがないと、復元プログラムがあっても受信者はファイルを開けない バインディング binding: テキストデータに文字色・サイズの様な情報を付加 バインディング形式ファイル: ワープロソフト文章等APソフトの保存ファイル トレードオフ: バインディング↑ = 表現↑ ⇔ ファイルサイズ↑ = 処理速度↓ テキスト形式ファイル: バインディング情報省いたテキスト部分のみファイルAP利用ファイルは、通常、装飾用バインディング情報用領域を予め用意している。この領域は、ワープロで黒色文字だけの文章を作る場合でも確保される。プリントアウトした印刷物では同じに見える黒一色で文字飾りの無い単なる文字文章を、エディタで作ったファイルとワープロで作ったファイルサイズ(ビット数)を比べると20倍以上違うことも珍しくない。文字だけのemailをワープロ添付ファイルで送るべきではない問題がここにもある 進化と再利用バインディング情報は、普通ソフトウェアメーカー毎で異なり、異なるソフトで作られたファイルは相互利用できず、「互換性」がない。テキストのみファイルは、最も互換性が高いファイルとなる。ファイル互換性問題は、同一メーカーソフトでも起る。ソフトは、ユーザの声を聞きながら改良されるが、改良で、新機能追加の他、旧機能廃止もあり、同メーカーソフトでも、バージョンアップで読み取れなかったり異なる働きをする場合がある。互換性問題は、プログラミング言語でも起る(泣ける)。ソフト利用時は、ソフト進化を頭に置き、将来利用可能(再利用)ファイルは、必要に応じファイル変換する等の対応が必要となる。ソフト改良は生物進化に似て「進化」と言われる互換性が無いと再利用に不便: 普及ソフト作成ファイルは、別メーカソフト利用のためにファイル変換ソフトが開発されるが、変換は双方共通部分という制約がつく。バージョンアップは、新機能追加が多く、「旧ソフトファイルは新ソフトで扱えるが逆はダメ」が常である(上位互換 – Micro$oft製品にはない) Q 再利用を文書ファイル利用の他に、体育大会プログラムのように類似形式を何回も使う時は雛形を作り変化部分を差し替え作業効率を上げる。ワープロ文書・表計算、プログラム等の再利用を調べよ バイナリー(binary)データとバイナリーファイルプログラムでCOPYと書くと32b (8 × 4)必要だが、プログラム言語の様に命令数が256以下だと8bで全命令対応コードが作れコンパクトになる。「全国国民体育大会 = 国体」、「personal computer = パソコン = PC」と同じである。プログラムをコンピュータ実行形式変換すると、コンピュータで実行可能な機械語変換され実行ファイルは大きくなる。「レスカ3」と注文を聞いた人は、「レモンスカッシュの元を3人分用意し、3つのカップに入れ、炭酸水と氷を入れ、レモン片を乗せ仕上げる」と考える。この作業手順置きかえが実行プログラム展開である数値表現コンピュータは、当初は計算目的に発明された。365という数値は、コンピュータ内部で「3 6 5」という数字コードをつなげたビットパターンで数値表現しているわけではない。数字は文字の1種としての記号であり、数値を表現しているのではない。普段使う十進法数値は、それに対応させた2進法として符号化される。数値符号化には、文字に見られない問題がある
正整数に限った表現二進法表現を位取り原理に従い計算した結果を十進法数値と対応させるもので、0以上の整数(非負整数)をビット列表現する場合、2進数表記が一般的Ex. 3bを用いた2進数。(101)二ビットパターンを1 × 22 + 0 × 21 +1 × 20で示す整数値の5と見る。2B (16b)固定長に適応すると2バイト表現ビットパターンは65536だから0から65535までの正整数が表せる。このように2バイト全部を0と正整数に対応させる方法を「符号なし整数」という
数______0__1___2__3___4__5__6___7 a2 – b2 = (a + b)(a – b)はコンピュータでは必ずしも成り立たない。3ビット表現でa = 3, b = 2とし計算すると、左辺は32 = 9でオーバーフローが起こり、右辺は(3 + 2)(3 - 2) = 5 × 1 = 1で桁溢れしない。コンピュータで正確に計算させる工夫は頻繁に必要となる(「数値計算 numerical calculation」分野) 正負の両整数表現: 負数まで表したい場合 Ex. 16b = 65536のパターンに0と正負の整数を割り当てる方法 符号なし整数と同様表現で全パターン半分の0000000000000000=(0000)十六から011111111111111=(4FFF)十六を0から正整数32767に割り当て残りを負整数に割り当てる。問題は、残る1000000000000000=(8000)十六から111111111111111=(FFFF)十六までのビットパターンに負整数に割り付ける規則である。当然計算上うまく扱えるよう対応させる必要があり、そのように考え出されたのがコンピュータで多く使われている2の「補数表現」である補数による負の数の表現負数表現を考えるポイントは、絶対値が同じ正整数と負整数を加えると0になることである。二進法の足し算の基本規則は次の単純な4つに過ぎない足し算: 1. 0 + 0 = 0 2. 1 + 0 = 1 3. 0 + 1 = 1 4. 1 + 1 = 10 この計算規則をもとに、各正の整数と、負の整数候補に残したビットパターン 1000000000000000(8000)十六から111111111111111(FFFF)十六 と正の値との足算を行うと面白い規則ある。簡便に3b = 8種類のパターンで行ってみる。負以外の整数は0 1 2 3の4種類で、それぞれ(000、001、010、011)に対応ずけした。問題は残りの負の整数-1 -2 -3 -4を候補パターン(111、110、100)にどのように対応させるかである。絶対値が同じ正の数と負の数を加えるとゼロ(0)になることを考え、幾つかの組合わせの計算をすると、次のような興味深い組合わせが見つかる
表. 正の数と候補パターンの和の例
011 + 111= 1010 下3 桁の010 は、十進法表現の2
1- 1 = 1+ (1000- 1)-1000 = 1+111-1000
数 0 1 2 3 -4 -3 -2 -1
十進法 二進法 比較 メモ 計算機整数処理: 32bや64bの2の補数表示多用 → 32b: 10進数で10桁程度まで扱える Q コンピュータは、表で示した対応で正負数値を扱う。表で間違いなく計算できるよう、オーバーフロー対応規則を見つけよ。(ヒント)色々な場合の組合せを行い、規則発見する ある正数の2進法表現のビットパターンAが与えられた時、全ての1と0を入れ替え出来るビットパターンを、「Aに対する1の補数」という。「1の補数」に1を加え出来るビットパターンを「Aに対する2の補数」といい、コンピュータでは、絶対値Aに対する負数(-A)として扱う。なお、「2の補数」を使った0及び正と負の整数を扱うやり方では、最高位のビットが0の時は正、-1の時は負となる。このような方法で正と負の数の表現を補数符号付き整数という 2の補数を使うと、今のように引算が足算でできる。足算回路1つで加減という2計算ができ、コンピュータの演算回路を単純にできる。しかし、2の補数を作る回路が複雑なら意味がない。機械的にビットパターンを反転させるという回路は足算回路よりなお簡単なので問題ない Q十進法で「12345-5678」「5678-12345」を、2の補数を利用した16ビット2進法表現で行え Q 16ビット表現の符号付き整数で扱える整数は-32768から32767に過ぎない。このため、より大きな整数を扱う32ビット表現(4バイト)も利用される。32ビット表現」で扱える符号付き整数の範囲を確かめよ 実数表現 数値計算で本物の実数は扱えない 実数表現は「小さい値を単位に」表現できるが、(絶対値が)非常に大きい数や小さい数を表すには不便で、指数方式(浮動少数点)を使用する。電卓に指数部と仮数部(有効数字部分)を分け表示/計算するものがあるが、それと同じと考えればよい。この方法では次の情報を組合わせ1つの数を表現する 全体符号(1b): 数正負を表す 仮数値: 0-1の値を適当な刻み幅で表す 指数符号(1b): 指数正負を表す 指数値 2進数だと見にくいため210 = 1024だから指数も仮数も10bずつ(全体では符号を含め22b)で仮数は0:000-1:000(0:001きざみ)、指数も0-1000の値として10進数の形で表す。
↓全体の符号__________↓指数の符号
○ 1:000 101000 表せる数で絶対値が最大
× 3:142=0:3142 101 仮数部は3桁までしか表せない 実数表現は、定ビット数で表すため、整数同様、「表せる最大値・最小値」がある。実数では「表せる最少刻み幅」も問題である。コンピュータ上の実数は数学上の実数と違い「近似値」になる。コンピュータでは、実数表現に64b以上使用し、より細かい数値となるが、原理は同じで限界があることは変わらない 数値表現と誤差実数取扱い時に十進法計算でも見られるがπを3.14とし計算するとπは無理数(3.14159…)で誤差がある。分数2/3は0.666…という無限小数である。誤差は、有限桁でしか扱えないコンピュータで必ず出る。コンピュータ計算では、別種類の誤差が存在し、十進法では有限確定値となる小数が、2進法で数値を扱うコンピュータでは無限小数になり、有限で打ち切るための誤差であるEx. (0.2)十 = (0.011011011……無限に繰り返す)二 十進法の0.2は、単位1の1/10 (0.1)十の小単位2個分だが、それを2進法で表す。2進法の(0.1)二に対応する小単位は、単位1の1/2(十進法の0.5)で大きすぎる。そこでこの小単位の更に1/2(十進法の0.25)、更に1/2の単位(十進法の0.125)というようにより小さな単位を作り、それらの組合わせ十進法の0.2を作ると(0.00110011011…)二となる。この関係は1/3を十進法の小数で表わすと(0.3333…)十と無限小数になるが、三進法なら(0.1)三となるのと同じである。計算に伴う小数誤差を小さくすることは数値計算分野の研究対象である Q「仮数5桁 + 符号、指数2桁 + 符号」表現で次の計算を実行すると結果はどうなるか。その違いはなぜ生じるのか 1) 3.1416 - 3.1234 + 0.0000001 2) 3.1416 + 0.0000001 - 3.1234 ※ 指数部も仮数部も表せる桁数は固定される。(10進数)指数2桁 + 符号、仮数5桁 + 符号とすると、10000000000 = 1.0000 × 10+10, 0.0000000001 = 1.0000 × 10-10等の値は表せるが、これらを足すと10000000000.0000000001 - 1.0000 × 10+10と近似値に丸められ、「0以外を足しても値が同じ」になる。123456という数値でさえ、123456 - 1.2346 × 10+05、のように概数でしか表せない。実際のコンピュータでは指数部も仮数部ももう少し余裕があるが問題は同じで、有限ビット数のデジタル表現では原理的に避けられない制約である文字数値混在ビットパターン読取コンピュータ使用目的は、情報処理結果を得るためで、文字数値表現決めただけでは不十分である。単語を知っていても文法を知らなければ文章を作れないよう、ビットパターン表現された文字数値の集まりは処理手順を書いたプログラムに従い読み取らねばならない。文字と整数型や実数型の数値が混在したファイル(ビットパターン集合体)から、文字数値読取り方を見てみる2B(16b)ビットパターンで数値表現すると、JIS漢字コード表現と重なるものが出てくる。文字では使わないビットパターンということがあるが、数値を一定長ビット表現する場合、数値の性格から全パターンが起りうる。この重なり問題を解決し、誤りなく「今は数値ビット列」「次は文字」とプログラムが解釈できるよう、要素となる文字コードや数値コードの集まりは工夫しメモリー配置される。基本は固定長と分離記号をもとに、「読み取り文法」を作る Ex. 仮想的に読出し規則決める。データファイルは次の規則で読み出す。ファイル先頭1bは文字か数値を指定し、0なら文字、1なら数値である → 0の時(数値)
+ 2b: 数値種類
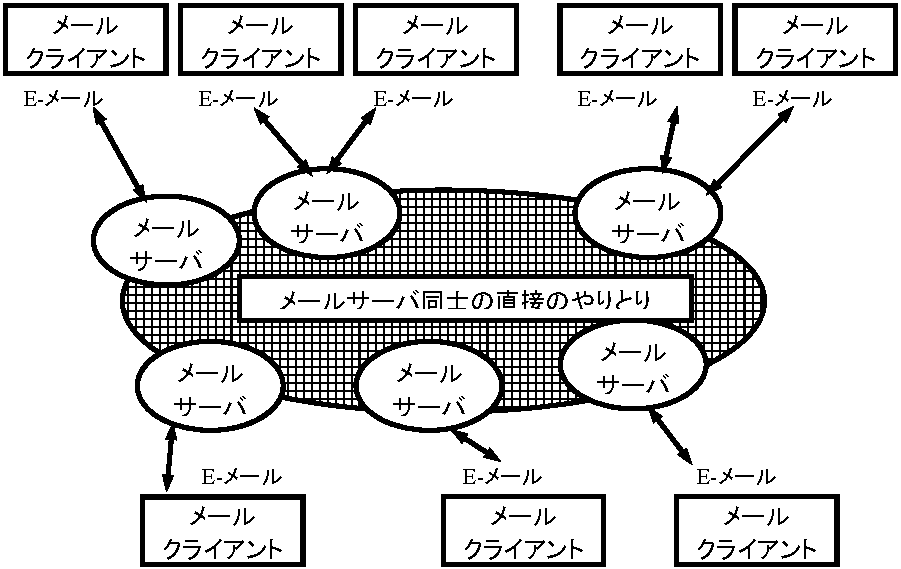
+ 2b: 文字コード種類 デジタル信号とアナログ信号digital singal and analog signal文明・文化は、文字や数値という「記号」や、絵画、音楽、重さ、電流の値といった「モノの状態」、食料、衣服といった「モノ」自体により出来ているが、記号表現できる情報は、ビットパターンに限られた。それは、記号が「数えることができる」性質を持っていたからであるデジタル情報: 「2N通りのどれか」というビット列の形で表される離散的情報 アナログ情報: 長さ重さ等のように連続的情報のこと → 量子化: アナログ情報を最少の細かさを定めデジタル情報に変換すること デジタル情報は「中間的状態」がない(離散的)、離散量からなる。離散量は、電磁気的に2種類のビットから作られる組合わせパターンに対応させコンピュータ処理が可能となる。一方、連続的情報をアナログ情報といい、その量を連続量(アナログanalog量)という。重さは、1 gと1.1 g間に1.05 g、1.032014…というように無限の値が可能である。これらは、通信ではデジタル信号、アナログ信号という コンピュータは、正確にはデジタルコンピュータというデジタル情報処理機械である。アナログ情報は、テープレコーダーや電話のように電磁気的表現されてもアナログ情報でありコンピュータ処理できない。アナログ情報をコンピュータ処理するには、デジタル情報変換が必要である。アナログ情報をデジタル情報変換処理する背景には、デジタル化の手間を上回る利益があるからである。実用的には、一定の値を単位とし、それが幾つあるかという形に読みかえアナログ情報をデジタル情報変換する(量子化)。ヒトの身長を表すには1 mm単位で十分だろう。身長は4 m以下だから212 = 4096で、ヒトの身長は12ビットデジタル情報で表せるが1 mmより小さい部分の情報を捨てていて、これを量子化誤差という。より精度の高い値が必要ならより多くのビット数を用いる Q 情報で、主に1)アナログ情報、2) デジタル情報、3) アナログでもデジタル情報として扱われるものを考えよ アナログ情報の伝送と記録振幅変調 amplitude modulation, AM: 搬送波強弱で情報伝達周波数変調 frequency-modulation, FM: 搬送波周波数変化で情報伝達 アナログ伝送: 情報源(音源)のアナログ情報(振動)を「そのままの形」で別媒体(メディア)の状態(振動)に写し取り送る方法 Ex. 「おはよう」という言葉の伝達: 声帯が「おはよう」と振動 → 声帯振動はその振動状態を写し取る形で周りの空気を振動させ広がる → 空気振動が鼓膜に届く → 鼓膜は空気振動を写し取る形で振動 = 伝達完了 Ex. 機器アナログ信号伝送: 空気振動をマイクで電圧に変換し、時間と共に電圧変化する様子を伝送し、受信側でそのままの形でスピーカに送り再生
アナログ伝送の問題減衰、雑音通常会話は、空気を媒体に行われるが、伝達媒体は変更でき、糸を使うのが糸電話、電流振動が電話、電波が無線電話である。音伝送は、途中の伝送媒体が変わっても、「発信側-アナログ状態媒介物-受信側」という仕組は変わらず、アナログ伝送には、次のような問題点がつきまとう
会話 🔊 ────────> 空気(気体振動) ───────────> 👂 雑音(ノイズ) noise: 取り扱う情報を歪めるもの全て Ex. 雷でテレビ画面乱れる = 画像情報電波に雷電波が加わるため ノイズ: 積み重なる性質 = 個々ノイズは小でも伝送長くなるにつれノイズ増 減衰対策に、減衰しにくい媒体開発や信号増幅が行われるが、増幅はノイズも増幅させる。雑音対策に、雑音を拾いにくい材質開発、ノイズを通さない性質のフィルタ装置を挟み除去が行われるが、フィルタで効果的に取り除けるのは、元信号と性質が大きく異なるものに過ぎず完全除去できない
アナログ記録の問題記録媒体の劣化鼓膜(振動膜)に針をつけ回転板にあてると針の振動に応じ溝が刻まれ、この溝に針を置き板を同じ回転で回すと針は溝形と同じ振動をし、それが振動膜に伝わると音が再現できるのが、レコードの基本原理である。情報源状態を、「そのまま」記録媒体にコピーするのがアナログ記録の本質である。アナログ記録(伝送)は、情報を元状態で取扱う限り、減衰、雑音、劣化問題が付き纏い、アナログ情報技術は、これらの克服にあるといえる劣化: 記録媒体は時間と共に変質し、アナログ情報では劣化は避けられない Q アナログタイプ複写機で新聞(オリジナル、親情報)をコピーする。コピー(子)から、更にコピー(孫)する。この操作を、曾孫…と何度も繰り返し、画質の落ちかたを確認してみよ。カセット、ビデオでも確かめよ アナログ情報のデジタル化発想の転換芭蕉筆俳句の短冊は、短冊の骨董的「モノの価値」と、俳句表現の「意味の価値」がある。「意味の価値」は、短冊に虫食い(雑音)があっても、離れて見える文字が小さくなっても(減衰)、墨跡が薄くなって(劣化)も、読めれば価値は変わらない。点字でも同じである。アナログ情報のデジタル化の本質は、これに深く関係する。コンピュータ内部やデジタル通信は、ビットパターンを電気パルスpulseで扱う。1電気パルスを電流波形(アナログ情報)に注目すると、波形は電線を流れるに従い、雑音の影響を受けたり減衰する。波形でなくパルスが「来た/来ない」なら1パルスが1つと認識できればデジタル情報価値は減らない
アナログ情報とデジタル情報の相互変換アナログ情報をデジタル情報で表現できれば、アナログ情報の持つ諸問題 (Ex. 伝送・記録、複写時におこる減衰、雑音、劣化) が解決できる。カメラで撮影したカラー写真は、時間と共に変色するが、デジタルカメラ撮影写真に色の劣化は起こらない。記録媒体が時間的に品質低下を起こせば読めなくなる恐れがあるが確率は低く、デジタル信号は、親、子、孫と何段階複写しても品質劣化が起こらないため、バックアップコピーにより解決できるMemo 音楽無断コピー = 著作権違反: アナログダビングは、音質劣化から不法コピー問題表出しなかったが、原本(オリジナル)と同一物の複製ができるデジタル情報記録技術出現により、不法コピー問題は深刻化した。デジタルレコーダーでは、原本コピー時に複製と分かる仕組で複製禁止をしている。不法コピー問題は、情報社会で深刻になった問題の一例である アナログ/デジタル変換 (A/D変換analog/digital conversion): アナログ情報をデジタル情報に変換すること AD変換器analog-to-digital converter, AD converter (ADC) ↔ DA変換器digital-to-analog converter, DA converter (DAC) PCM, pulse code modulation: アナログ音声信号のデジタル信号変換方式音声をA/D変換し伝送すると、音声波形ではなく電気パルスでビットパターン伝送され、受信側がそのまま聞いても音声認識されず、デジタル情報をアナログ情報に戻すデジタル/アナログ変換をする。細かい時間間隔毎に電圧を調べ(サンプリング)、電圧大小をデジタル化伝送し44000回/1秒(44 kHz)等のサンプリングを行い、各サンプル値を16b表現(音楽CDも同様デジタル記録法) MIDI, musical instrument digital interface: 譜面・演奏手順等データを電子楽器間やPC-楽器間で通信する仕様。Ex. 通信カラオケ譜面データ 音声表現形式音声情報圧縮表現方式規格(音声表現形式名) Ex. μ-law、AIFF、WAVWAVE (.wav): Windows無圧縮標準音声ファイル形式。多くのプラグイン/ソフトウェアが対応。WAVEファイル作成・配信にはWMP 7開発ツールのエンコーダやフォーマット必要 MP3 (.mp3): MP3(MPEG Audio Layer-3): MPEG-1音声データ圧縮技術のみを適用作成した音声ファイル。CD並音質を保ちWAVEファイルを1/11に圧縮する。下位技術のMP1 (MPEG Audio Layer-1)は1/4,MP2 (Layer-2)は1/7の圧縮率。再生はWinamp, WMP, RP 8 Basic等でできる MPEG, Moving Picture Experts Group: ISO設置の動画技術専門家組織名がファイル形式名称になった RealAudio (.ra/.ram): RealNetworks社(旧Progressive Networks)開発音声データ圧縮音声ファイル。RealAudio再生用プラグインであるRealAudio Playerは、Internet ExplorerやFireFoxに標準装備だが、開発元RealNetworks社の上位プラグインである RP 8 Basic等で再生も一般的AIFF (Audio IFF) (.aif/.aiff): Macintosh標準音声ファイル形式。再生用プラグインはQT Playerだが、WMP 7, RP 8 Basic等も対応。ファイル作成配信はQuickTime上位製品QuickTime Pro (有料)が必要 Advanced Streaming Format (ASF), (.wma): Windows Media Audio: Microsoftマルチメディアファイル統一ストリーミング方式ASF音声データ圧縮方式でCD並音質再現可能 Advanced Audio Cording, AAC (.aac): 映像データ圧縮方式MPEG-2/4中、音声データ圧縮技術のみに適用作成された音声ファイル。MP3より圧縮効率1.4倍高い。再生にK-jofol対応 AU (.au): AU (Audio)はUNIX標準音声ファイル形式。再生にWMP 7, QT, Winamp, Plugger等も対応 アナログ/デジタル変換原理A/D変換 = 標本化sampling → 量子化quantization = 2段階
標本化: アナログ情報波形が、時間軸に沿い等間隔Wtの点列、T0; T1; T2; … Tnをとり、その波高値を読み取る
アナログ/デジタル変換に伴う誤差問題と標本化と量子化の基準A/D変換で得たデジタル情報は、伝送等ではアナログの持つ雑音等の諸問題は起りにくいが、A/D変換(デジタル化)中の標本化と量子化の段階で誤差が入る。標本採集の時間間隔Wtを小さくし、量子化刻み個数(N)を大きくすれば誤差は減らせる。標本化間隔を無限に狭くし量子化の刻み個数を無限に大きくすれば、完全に元情報を再現できるが、誤差を減らすほど情報量が増えるトレードオフが起こる。トレードオフ問題は、音では人に聞こえない音を扱わないことで解決を図る。音の性質は振動周期(振動数)と振幅で決まるが、「アナログ波形最大振動周期(最大震動部分)の半分間隔で標本化すれば、元波形復元可能」(標本化定理)なため抽出間隔Wt基準値が決まり、音の強弱の違いを聞き分けられる能力(聴力分解能力)から量子化レベルNが求まるQ電話経由のCD音楽が、直接聞く音と違う原因にA/D変換がある。理由は何か。(電話は声を基準に作られ、聴力は20-2000 Hz/s (1回振動/sが1 Hz)程度の音域を聞き分けるのに対し、人間の声は100-3000Hz程度の音域しか出ない。楽器音域は声より広く、大きな音が出る) 時間変化するアナログ量をA/D変換利用するには、誤差問題に加え処理時間問題がある。1/103秒間隔で標本化しN = 256で量子化したとする。量子化値に対応する電気パルス1b分幅が1/103秒とし、それを1本の電線で8ビットパルスを順に送るのでは波形は最低8/103秒に引き伸ばされ実用化できない。8本の電線で一度に送る、パルス幅短くする(1秒間処理数増やす)等の工夫が必要となる。32b CPU 400MHzは、1秒間処理パルス数や同時処理ビット数を示し、この値からコンピュータ性能の目安がつく ウェーブテーブル wave table は、「生音」標本化した波形データで、GMでは128音を規定する |
[三大革命]
コンピュータ社会のもたらすもの電気製品内蔵マイクロコンピュータ → 高度サービス提供: 製品差別化行える便利な商品マイクロコンピュータ組込家電: 多くの家庭電気製品(家電)に組込まれる
Ex. 音楽ダビング: 内蔵コンピュータが時間計算し長さに応じ曲順替える
システム: 交通管制 + 電話網 + 社会保険 + 住民DB + 電子決済 + 在庫物流管理 + 銀行証券オンライン + 住民票DB + 無人交通 + 自動制御 + 図書館DB + 特許情報 + 意志決定支援 + 気象予報 + POS + 在庫管理, etc. = 社会
_交通制御 ←←←←←←← 交通制御 ←←←←←←← 交通制御 図1.3 交通管制システムのシステム構成図 交通管制システム: ハードウェアは、交通量測定センサー・信号機・周辺装置と通信回線・コンピュータで、ソフトウェアは、通信制御・データ解析・信号機制御プログラム等で構成される。車の円滑な流れには、複数信号機連携必要で、信号機を1コンピュータで集中制御したり、地域毎の信号機制御用コンピュータを通信回線接続しコンピュータ間連携を図る分散制御方法がある
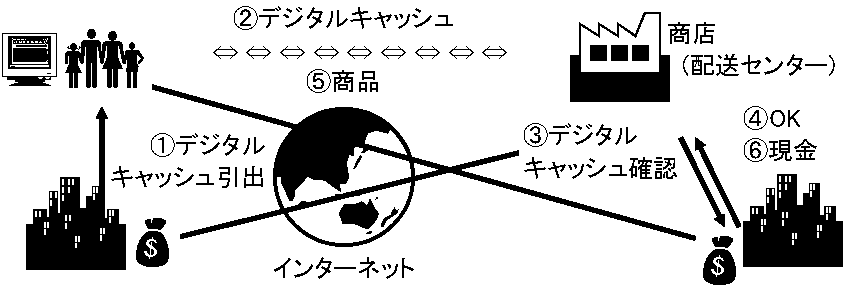
Ex. 高速道路料金集金システム: 車から出る電波で車特定 → 車移動経路求め高速料金を銀行口座から自動引落し → 料金所付近混雑緩和 情報システム時間や場所の制約を緩和Ex. 銀行 (過去 = 現金引出は営業時間内に窓口へ通帳印鑑を持ち行く) 現在 = 預金者預金残高NW管理。預金者から預金や引出があるとNWで預金残高調べ適切処理を行う。現金自動支払機で銀行窓口終了後も引出せ、ネットバンキングにより携帯コンピュータで残高照会や振込ができる。デジタルキャッシュdigital cash (DC)で買物もできる。お金は物と交換する象徴の一型であり、デジタルデータは現金同様に使え、お金と等価となる。DCは、暗号化デジタルデータが現金同様に扱え、通信回線を通じ送付できる。紙幣硬貨を運ぶには物理的手段をとるが、DCはemail等で添付送信も可能となる。ネットバンキングサービスでは、携帯型コンピュータを持てば現金自動支払機を持ち歩くのと同じで、いつどこでも引出振込できる。印鑑に変わり「暗証番号」を使い認証できる。利子計算や他銀行等への振込にもNWは活躍し、日本貨幣の外国貨幣両替に銀行は予め外国貨幣を用意するが、貨幣はNWを通じ海外取引を使い入手するのが普通である
→ スマートフォン Ex. 商品流通: 大量の流通情報や価格情報等がNWを使いやりとり
金融業: 預金残高・貸付金額管理等にコンピュータ使用。外国為替取引等: NW取引 プッシュ型とプル型 - 主体的に情報を得るプッシュ型メディア: 受信者が意思選択なしに得る情報 Ex. 広告チラシプル型メディア: 受信者が積極的に得る情報 Ex. W³ (WWW) = 閲覧しなければ情報は得られない → 必要な時に情報源のサーバに取りに行くため最新情報が得られ無駄な配送がない → W³ (ニュース自動配信サービス等プッシュ型もある) 新聞広告は地域限定できても読者の興味に応じ配り分けできないが、インターネットニュース(NN)自動配信では、アンケートに答えると、それに基づく内容のみ配信される。あるカテゴリ分類された情報が入手できても、送られる個々のニュース内容を自分で選択した訳ではないプッシュ型メディアとなる。情報社会では嗜好品検索容易となり、プッシュ型メディアと比較し主体的に情報入手する方法の割合が大きい特徴があるQプッシュ型情報とそうでない場合(W3検索等)の情報発信側、情報受取側、情報内容による差違を考えよ
欲しい物を安く買う = 情報収集必要: 価格と値段の情報 情報発信量に限界 + 商品の存在知らず入手できないことも 情報公開インターネット = 行動範囲越えた情報入手可 → 産業形態変化・新産業誕生店: 情報伝達ないと販売促進不可 → 情報発信格差は利益に直接影響 → 売上向上のため情報公開 企業経営: 情報公開は企業独自性の追求でもあり、他社を越えた技術やサービスを知る 消費者: 情報収集は生活向上に不可欠 → 自主的に(商品)情報集め購入する消費スタイルに変化情報発信しない店(企業)は無視 Ex. W³ページ広告出し消費者が情報検索購入する消費形態 → 相乗効果で情報社会発展情報処理技術と企業の関わり
検索エンジン等使い消費者は豊富な情報得る → 検索され易いページ作成必要
生活用品等購入 + チケット購入 + 公共料金支払 + … Ex. 3. POS (Point-of-Sale) システム: 通信と繋がったキャッシュレジスター バーコード barcode: 商品コード(国・企業・企業内商品コード)を記録 → 商品価格レジ入力省力化 値段変更は商品値札を付け直さずバーコードデータベースの商品価格変更するだけでよい
コンピュータ通信利用喫茶店: 店員は注文を携帯通信端末に入力 → 入力データは厨房とレジに同時転送 → 客にレジ清算用コード振った伝票渡す → 客が店を出る際、レジ係は伝票コードをバーコード読取機でキャッシュレジスターに読み取らせ、レシート作成し代金を受け取る(ここまでは普通の喫茶店) Ex. 4. 企業情報システムでのコンピュータ利用と情報発信
文書電子化 → 出退勤管理、購買管理等がペーパーレス化 + 電子決済 企業内では経理・人事・稼働管理、プロジェクト管理、顧客情報販売管理、在庫管理、情報共有等の各システムが社内LANで接続され、イントラネットを構成しDBは連携される Ex. 市場-工場間業務プロセスを見直し、情報システムを導入しタイムリーに市場ニーズに合う製品を企画生産でき、品揃えが充実し見切りロスが減少し不良在庫を減らせる。個々の顧客取引履歴を蓄積した顧客DBは、営業力を高め顧客満足度を高めるが、販売管理システムと顧客管理システムの連携が不可欠となる(分散システム) 分散システム: NW上で複数システムが協調し動くシステム → 分散型計算機 distributed computers機能分散: 各システムの目的別に各コンピュータ分散配置される形態 オーブ (ORB, object request broker): NW接続した複数コンピュータに分散したオブジェクトの所在を気にせず1台のコンピュータで動くかのように利用するソフトウェア 負荷分散: 同プログラムを複数コンピュータ起動し、入力処理を各コンピュータに振りコンピュータ負荷軽減→ 並行処理 real time and parallel programming クラスタシステム cluster system: 複数サーバで構成するシステムを1台のサーバに見立てたもの
フェイルオーバー fail over: クラスタシステム等でシステム障害発生時に実行中の処理を他コンピュータに引き継ぐこと
🏢 社内NW(イントラネット) 図1.5 企業情報システムの例 高額商品購入時には競合商品とデータを比較検討し嗜好商品を選ぶため、商品情報発信により情報付加し商品価値を高められるEx. 商店生鮮食料品売場に料理レシピ置く → 消費者は、レシピで食材を決め、商店では生鮮食料品に情報付加し商品価値高め売上げ伸ばす 情報化で、経営効率化とスピード化を促進し、経営者は情報を素早く得て、より的確な意志決定が可能になるが、過去の経験等に基づき創造力を発揮した戦略を立てる意志決定は、今のところコンピュータはできないQ 商品やサービスに情報付加し価値を高めた例をあげなさい Q 企業における情報公開の利点と欠点は |
CAD, computer aided design: コンピューター支援設計
2DCAD: 2次元CAD → 3DCAD: 3次元CAD CADD: CAD(製図) CAID: CAD(デザイン) CAAD: CAD(建築設計)CAM, computer aided manufacturing: コンピュータ支援製造 ≈ コンピュータ制御機械自動的稼動 (CADCAM = CAD + CAM) CAE, computer aided engineering: コンピュータ支援技術
シミュレーションや解析による検証 → 実物実験に変わる 建築設計: コンピュータシミュレーション (Ex. 建造物強度・地震影響、ビル風影響、ビル影影響等を建築前に予測 → 結果はemail等で関連企業へ転送 工場内生産機器をコンピュータ制御し(半)無人工場実現
______🏢______⇒ 設計図データ ⇒__ 🏭 🚗🚗🚗
組立必要部品設計 = CAD製図システム使用図面作成 ⇒ Ex. 6. 農業・漁業(第1次産業)と情報処理 → 生産活動効率化に情報処理技術導入 NWシステム → 特定農産品出荷時期を制御し安定供給。漁獲の多い場所をDB化し効率的漁業 農業: 農作物植付効率の良い時期・畑の位置等を、気温・土壌等を元に判定 + 植付・収穫・出荷機械制御漁業: コンピュータで運航制御、魚群探知器制御 → 農作物・魚出荷: 商品流通システムを活用 情報産業日々、新情報処理技術が開発され新NW使用法が発明されている。情報そのものや情報処理を商品にする企業もある。情報処理に必要なソフトウェア・ハードウェアを商品とする企業もある
情報化の影の部分情報処理技術は使い方次第で、企業の生産性を下げたり、プライバシー・企業秘密が洩れたり、犯罪につながる。入力情報が外部に洩れると困る情報は、セキュリティ対策を講じないNWを用いた掲示は危険である。国際標準化機構(ISO)は、文書管理方法規格を定め多企業がISO基準管理手法に従い文書管理しているQ 各産業におけるコンピュータ活用とその効果を考えよ。コンピュータがないと、その産業はどうなるか バグ bug: コンピュータの動作に影響を与えるプログラムミス
コンピュータ停止事態生じたり、誤動作し死傷者を生じた場合、プログラマは傷害致死罪に問われることもある デバッグ debug: バグを探し、取り除くこと デバッガ debugger: バグ発見・修正作業を支援するソフトウェア ベータ版 β version: バグ発見に開発中に公開されたソフトウェア等 公共システム: システム信頼性高める技術としてデュプレックスシステムduplex systemやデュアルシステムdual system等、ハードウェア多重化 ハッカー hacker: コンピュータ不正侵入技術持つ人(+ 不正侵入者) = 犯罪者ウィルス(computer) virus: 保存ファイルを破壊したりするプログラム群
感染防御: 見知らぬemail開かない、ウィルスチェック後にファイル転送を行う、定期的ウィルスチェック行う、等 情報システム評価= 総合評価 = 機能 + 信頼 + 使用 + 効率 + 保守 + 移植 + 保全 + 安全信頼性向上技術: ハードウェア多重化 + ソフトウェア対処
フェイルソフト fail soft: システム故障時に性能低下しても運転続行 人間がデータ入力すると、誤入力避けられない。対し、チェックディジットを付加し、ソフトウェアで誤データ入力をチェックするのも信頼性高める一つの方法 Q 流通業、医療、エネルギー、建築等の分野での情報化システムの特徴と技術を調べよ。 明日の情報社会
🏠 🏨 チームメンバー MFP (multifunction perpheral): FAX、コピー、プリンタ、スキャナを1つにした機械。合州国でSOHO向けビジネス機器とし注目される コンピュータ内蔵家電製品同士が高度化相互通信し新生活スタイル生じる。音声理解し動作する電子ペットが作られ、躾方により電子ペットの性格が形作られる。電子ペットは大量生産だが、コンピュータ技術により持主の性格等に左右され電子ペットが個性をもつかも知れない 情報社会は、時間場所を越えコミュニケーションでき、チャット等では未知の人同士で対話できる。同じ趣味思想を持つ人達を容易に探せ、仮想的コミュニティを簡単に構成でき、将来は、バーチャル世界、バーチャルコミュニティが広がるだろう (Ex. バーチャル学校・親子・恋人)。CU-SeeMeというInternet電子会議システムは、「リフレクタ」と呼ぶnetwork上の下層電子会議室に接続し、互いの顔を見て音声で会議を行える 仮想現実: コンピュータ + センサー → リアル仮想現実を体験 飛行機パイロット訓練
コックピット窓にコンピュータディスプレイはめ込み、パイロット操縦により表示が刻々と変わる装置を用い飛行機に乗らず飛行体験可能
自宅で世界旅行 + 旅行中にコンピュータ合成画面上の人物と会話 遠隔地でも夜でも実施可, バーチャル商店、遊園地、デート等も可 リモート手術通信回線により病院同士を結ぶ – 既に行われている Q 身近な仮想的コミュニティと、インターネットコミュニティを調べよQ 1) 仮想現実可能性についてブレインストーミングしアイデアを出せ。実現した場合、生活や産業はどう変化するか? 2) 仮想現実により、障害者、老人等の生活はどのようになるか コンピュータは万能ではない!しかし、個性をもち人格(?)を持つことになるかも知れないコンピュータは、一般製品(家電・日用品等)同様、工場生産製品だが、一般製品とは利用目的の決定的相違がある。電子レンジは食品解凍・調理、乗物は物質輸送、と利用目的前提に作る。コンピュータは、多目的汎用利用前提に、部品(ハードウェアhardware)やプログラム(ソフトウェアsoftware)が組換えられ万能機械といわれる(しかし、プログラミング可能問題しか対応できない) プログラミング: プログラマがコンピュータ指示命令手順の記述作業
→ 人間が逐次考えた手順に従い、プログラミング実行 コンピュータは、創造力はないがヒトの創造力を刺激し高めることは可能である。コンピュータ対話を通じ新原理発見・発明も期待される。4色問題はコンピュータが解き、囲碁は人間が勝てない。理論的にプログラミングできても非実用的問題にも対応できない。巡回外交販売問題(指定都市を外交販売人が1回ずつ訪問する最短経路を求める問題)がある。囲碁等の最終的結果到達まで試行錯誤を繰返し解法を探す手順、即ち発見的(ヒューリステック)問題にも万能ではない。「2001年宇宙の旅」のHALは、先の話 個性・思想・性格がコンピュータデータ入力できれば、自分に似た思考のコンピュータができる。そのコンピュータと対談すると私は私と対談していると感じるだろう。私が死んでも、周囲の人はコンピュータを通じ私がいないことを意識しないかもしれないが、それでは私は死亡したのだろうか? 情報社会構築には、コンピュータや情報処理技術を恐れないために、正しい認識を持つことが必要である。システム作成時に、技術的問題だけによる判断でなく、生活や社会や環境に与える影響も考慮する 人工生命 artificial life, A-life, AL Ex. ボイド boid: 鳥モドキ birdoid の略 – 鳥の群れ飛翔シュミレータ Q コンピュータが人に近づくための必要技術を調べ、実現可能性を考察せよ
表. ヒト頭脳作業 vs コンピュータ
コンピュータによる頭脳労働外部化は、部分に留まり頭脳全て外部化できるかは未詳である。人工知能 artificial intelligence (AI)分野は、新原理コンピュータ開発を含め、人知性感情分野まで研究され、人間を幅広く解明する必要から、理系文系という枠組を超え共同研究が行なわれている
人間の頭脳
コンピュータ サイバネティックス(人工頭脳学) cybernetics: (電算機等利用)自動制御 cybernation |
|
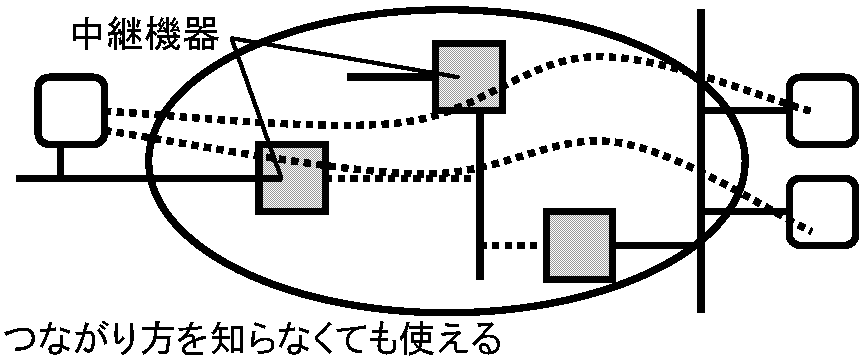
インターネットは、世界中のコンピュータを機器やケーブルで繋ぐが、電話網同様、繋がり方を知らなくても相手コンピュータ名(電話番号に相当)だけ知れば自由にやりとり可能(図1.1) Q「葉書」「新聞」「掲示板」の機能差、利点欠点を考えよ。「コンピュータ上」にあったら利点欠点の変化を考えよ
インターネット The internet: W³サーバ相互通信し情報交換可能にしたもの。The がつき大文字で始まる WWW (W³): インターネット上でWebページ単位で情報をやりとりする仕組 W³は1994年頃から普及し、Webブラウザはインターネットを通じWebサーバ接続し情報を取り出す Ex. TV放送: サーバ = 放送局(情報源) → ブラウザ = TV(情報受信手段) TVは送信範囲に制限 ↔ W³は全世界中のサーバ情報を受取れ混信ない。Webページは、テキスト情報に加え音声動画等の各種形態情報使用可能なためW³はマルチメディアシステムとも言う。W³は、「全世界に広がる蜘蛛の巣」で、ページが網目状にリンクしたハイパーテキストマルチメディア情報システムである (Web)サーバ server: 情報発信プログラムとそのコンピュータ(Webページ管理コンピュータ)(Web)サイト site: W³ページ管理場所 (Web)ブラウザ browser: 情報を見るプログラム → (Web)ページ page: 受け取る情報の単位 テキスト(情報): 文字の並びで表わされる情報 マルチメディア情報: 音声画像動画等、文字以外のものが混ざった情報 リンク link: W³サーバ参照指示書式 – ある情報中に他情報のありかを埋め込んであるもの ハイパーテキスト hypertext: 多数情報をリンクで相互関連したもの。マルチメディア情報中心ならハイパーメディア hypermedia 情報と呼ぶこともある プラグイン plug-in: ブラウザにマルチメディア情報を表示しする機能を追加するソフトウェア群。Ex. Shockwave W³で情報を見る (Look up information on the W3)ブラウザ起動: 表示ページ中に下線や違う色の文字等による表示箇所にマウスカーソルを乗せると、画面下端にリンク先「番地」が表れる。リンク選択すると、ブラウザ画面が切り替わり指定番地ページが表示される。操作はブラウザにより違う。W³はリンクと各種ボタン選択で情報を辿れるブラウザ表示起点ページを入口/ウェルカム/ホームページ等と呼ぶ → HPは、プレゼン全体・W³全体で、1 Webページ等は指ささない。ブラウザ参照を何でも「ホームページ」と呼ぶ人がいるが、誤解や行き違いがないよう注意 ホームページ homepage, HP: 「起点」は (1) ブラウザスタートアップページ, (2) サイト入口ページ, (3) プレゼン入口ページ等いろいろある URL (Webページの番地)W³が扱うNW中のもの(Webページ・音・画像等)に全てURL (uniform resource locator)形式の「番地」がつく。「http:」に続く部分がWebサーバ取り寄せページを表す。メール宛先や電子ニュース記事番号を表すURLはこの部分が異なる。URLは「番地」を3成分で統一的に書き表す。「//」から「/」間は、Webサーバ名、残りはサーバ中の情報格納位置である。情報伝達に幾つも方法があるため、それらを統一し書き表している電話番号、「番地」では、葉書・名詞・電話帳等で相手に伝えないと役に立たず、相手電話番号を知れば使えるのと似て、閲覧ページURLを伝えるため、広告を出したり、別ページからのリンク等の「伝達」が行われる 情報検索と集合演算ディレクトリサービスと検索サービスネットサーフィン: マウス操作だけで次々にW³を閲覧すること
ポータルサイトportal site: サーフィン起点を想定し作られたウェブサイト = ニュース等ユーザ関心度の高い情報 → ユーザの興味を持つ部分へリンクを辿れる Ex. Yahoo!, Netscape (s.l.) ディレクトリサービス: W³情報を項目毎に分類整理し探せるようページとリンクを構成したもの
↓ 全体
ールドカップ情報) ディレクトリサービスは情報が分類整理され、その分類に沿い探し必要情報に到達できる。ページ登録場所は人が判断するため、無意味な情報に到達することは少ないが、登録ページしか探せない弱点がある。情報分類方法は1通りでなく、「運動医学」は「運動」「医学」両方から辿れる。百科辞典と違いW³は頁を複数視点で分類可能だが全ては用意できない。ディレクトリサービスは頻度の高い分類法の枠組で分類する(サービス提供元により分類仕様違う)。慣れた分類法と違うと、探すのに時間がかかる 特定情報を探すもう1手段は検索サービスである。検索サービスは、Webページ入力欄に、1つ以上の検索単語(キーワード keyword)を打ち込むと指定単語を含むページを探す。条件を厳しくすれば、ページ数も減り、目的ページを見つける可能性が高まる(図1.9)。これを絞り込み検索と呼ぶ 検索サービス(エンジン): 適したページを検索するW³サービス Ex. Google |
検索#1: サッカー → 検索 Q 事柄を紙に書き、ディレクトリサービスで検索せよ。ルート記録をとり、分類法に違和感があれば原因も考えよ。次に、検索サービスで、絞り込み検索をし、各段階で、条件と検索数、含まれるゴミページの癖も記録する メディアと表現 (W³とコミニュケーション)メディア(通信)媒体) media: 情報伝達手段マスメディア(大衆メディア) massmedia: 多人数対象のメディア 表現 expression: メディアが運ぶ物理的なもの。新聞紙面、テレビ画像・音(音声)、見ぶり手ぶり、表情等NW通信技術ではケーブル等情報伝達材質を「通信媒体(メディア)」と呼ぶ。「メディア」と呼ぶ場合、より広い意味を持ち、マスメディアや、お喋り、電話、手紙等、人と人が情報をやりとりするもの全てが含まる 表現はメディアが情報伝達する道具と言える。これと比べ、情報の送手が伝達したいと思う事柄そのものを意図と呼ぶ。メディアには個々に固有の制約や限界があり、情報の受手に意図を完全に伝達することは原理的に不可能である。換言すれば、普通は、送手の意図と受手が受取った意図との間に不一致が存在する(図1.10)、不一致の現われ方はメディア種別により違う
送手の意図 [ 🐻 ] 受手が受け取ったもの [ 🐨 ] 情報伝達と評価通常、発信者意図はW³ページ(少なくとも入口ページ)に書かれる。広報ページならPR意図とすぐ分かる。自己表現目的ページは、ページ全体が「見て!」と語り掛ける。半面、業務作成、試作放置等、意図不明ページもある。結局、意図不明ページは(自分に)有用な情報を得るページではない1対1メディアは、疑問点を質問する等、やり取りし送手意図と受手理解との不一致を狭める。マスメディアには、その様な手段が少ない。送手が送ったものが事実を反映しているかは、表現だけでは分からない。送手はワザと偏った情報を送り受手を自分に都合のよい様に操作することすらある(情報操作) 情報操作やその他異常情報防御のため、
送手が嘘をついているとは限らない。複数の正しい情報中から、送手にとって都合の悪い情報を伝えず、都合のよい情報だけを伝えるというのは、情報操作の古典的手法である Q 普段良く見るページの意図を書き出せ。意図は明確か。またそれはなぜか Q 新聞を集め、共通記事を探し、内容や表現(見出し)の違いを比較せよ W³における情報伝達一般のメディアと異なる特性についてW3 = 強力なメディア ⇔ 大きな危険 • 基本的に発信者から受信者(複数)へ1対多・一方通行 - マスメディアに類似 • W³は情報発信者が自由にコンテンツ作成 - 1対1メディアに類似 • W³情報発信は、低コストで瞬時にアクセス可能になり、ほぼ検閲は無力
従来マスメディア: 編集者・プロデューサが発信前に情報整理しチェック。誤情報や社会的問題のある情報が流されれば読者が気づき問題点を正す社会的圧力が働く 誰かが問題に気づいても、訂正させるのは難しい。発信者に忠告しても無視されれば、他に取れる手段はない。世界中のユーザマシンにこのWebページは注意しろとポストイットを貼るのは不可能である 情報の正しさを読み取る意図の明確さと情報の正確さは別問題 → 情報の正確さ判断方法情報取材基本: 情報がその通りであることを、他の手段でも確認(裏を取る) Ex. 別Webページ、新聞、雑誌を調べる、情報源に直接確認 作者を知り信頼できるなら情報を信用する根拠 ↔ 別人が偽装している可能性 自分の経験や考えに照らし、ページ情報が正しそうかを判断する。ただし、「自分に好ましい情報だけを信用する」事態に陥らないよう気をねばならない Q HPを公開し、見た人が自分の意図通り見ているか調べる方法を考えよ Q 取上げたページの正確さを確認せよ。「自分の考え」は妥当だったか W³で発信者の要求に応える発信者は、ページ訪問者の反応を知る時や、積極的に意見収集目的に情報発信することもある。W³ではフォーム form と呼ぶ、アンケート形式で情報受手が発信者に情報を返す「記入用紙」機能がある。フォームに、記入欄等の「部品」が並び、回答を設定し提出ボタン(「提出」「送信」等)を押すと、記入内容が発信者に転送される。フォームは、一方通行だったW3を発信者受信者相互交信可能なものに変えたフォーム等に現われる典型的「部品」には、次のようなものがある
|
|
ネットワーク network = 電子情報NW・コンピュータNW 複数コンピュータシステムが相互に自律的に情報通信できるよう構成されたシステム(ハードウェアとソフトウェア複合体) ブラウザであるページを開くと、手元のコンピュータはそのページ情報をサーバから拾うが、キャッシュが残っていれば取り寄せを省略できる。どちらにするかは、手元のコンピュータ内部で自律的に判断している 自律的 コンピュータが、情報のやりとりを他コンピュータに指示されることなく独自に決定し実行すること Q 「ネットワーク」と呼ばれるものを挙げ、共通点や相違点を表に整理せよ NW通信路通信路 communication path: 情報伝達に必要Ex. 通信媒体: 電話は銅線、携帯電話は(基地局まで)電波 コンピュータ間通信: 媒体は光ファイバー(昔は銅線)が普通その上での伝送方式様々 → ケーブル規格(本数, 配線)繋がり方異なる コンピュータ使用伝送方式は、全て0/1から成る情報を伝えるデジタル伝送という点が、アナログ放送(テレビ・ラジオ等)と比べた違いとなる。1通信路が、何種類かの通信媒体や伝送方式を組合せ構成されることもあり、通信媒体や伝送方式が切り替え場所に中継装置が必要になるQ 使用コンピュータシステムに直接間接につながる通信路を調べ、接続様式を推定してから調べよ パケット packet: LAN内でやりとりするひと固まりのデータ OSIモデル: NW階層モデル。レイヤ1-7までが定義される(表) TCP, transmission control protocol: 伝送制御プロトコル。OSIモデルでトランスポート層プロトコル。パケット到着順序通りの並替えやエラー修正等は行われTCPより上からると2台のコンピュータが高信頼性専用線で結ばれた感じ TCP/IP, Transmission Control Protocol/Internet Protocol: インターネット標準通信プロトコル TCP/IPスタック: PCプラットフォームのみ必要。PCインターネット接続は、TCP/IPスタック、ソケットソフトウェアwinsock.DLL、ハードウェアドライバソフトウェア(パケットドライバ)必要 ソケットsocketは、BSDで普及した機構で、通信線終端を表すプロセス間通信機能の一種。NWを使うプログラムを書く時は、あるマシンのソケットと別マシンのソケットとの間でデータをやりとりすると考えソケットシステムコールsocketを使えばよい。UNIXに殆ど移植実装
Winsock, Windows Sockets: TCP/IPアプリケーション(AP)開発プログラム標準仕様のソケット DEC, Intel, Xerox共同開発(頭文字, DIX仕様)で1980年製品化したバス構造LAN(元々、X社研究開発用データ交換技術名称)。イーサネットはver.1, 2, ver.2と若干異なるIEEE802委員会作成CSMA/CD (carrier sense multiple access/collision detection)型LAN(IEEE802.3)がある。伝送媒体に50Ω同軸ケーブル使用、バス制御はCSMA/CD方式で最大伝送速度10Mbit/sec、ノード間最大長1 km、最大ノード数1024である。イーサネットは1伝送路を全利用者が共有し、送信はバス空きまで待つ衝突回避のため、バスが空くと同時に複数利用者が送信し衝突する可能性があり、各利用者は時間を置きデータ再送する。仕様はIEEE802.3規格化され、ケーブルから10BASE5 (thick), Cheapernet (10BASE2, thin), 10BASE-T (unshield twist-pair), 100BASE-TX, 1000BASE-x, 10GBASE-x他がある 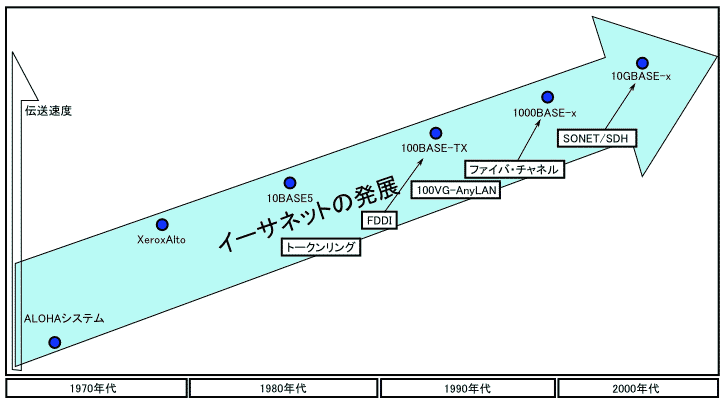 ブリッジ bridge: LAN内で同一MACプロトコルを使うセグメントとセグメントを(回線経由で)接続する装置
MACアドレス調べ別セグメントのパケットだけを通過させる Ex. ブルータがIP対応 → TCP/IPに基づくデータにルーティングし、IPX/SPXデータに対しブリッジとし働く ブロードキャスト broad cast: LAN内での一斉同報。1データを複数マシンに送るためLAN内トラフィック増える
ブロードキャストストーム: パケット極端増 - 正常データ送受信不可 FDDI, fiber distribution data interface: 光ケーブル使用トークンリング方式LAN。転送速度は100Mbpsと速い トークンは更新許可証の意味で、リンク内流れるトークン情報を捕まえたコンピュータのみに送信権持たせ、衝突なしの回線共同利用を実現。主にethernet同士をつなぐ幹線(バックボーン)とし使用 RPC, remote procedure call: 手元マシン実行プログラムからNW上マシンのプログラムを利用する機構OSF提唱のDCE中核要素の1つで、呼出し側は、呼出し先が結果を返すまで処理を中断する同期型連携である。RPC別な連携方法にメッセージ連携があり、結果を返ってくるのを待たない非同期連携である レプリケーションreplicationは、NW上DB複製replicaに対し、更新内容を自動的に伝播する仕組みで、複数DBサーバ間でデータをやりとりし、DBの一貫性を保てる。マスターと、レプリカは同形式テーブルである必要なく、レプリカ側更新はマスターと同時の必要もない(非同期更新)NDIS, network driver interface specification: Microsoftが定めたLANマネージャのデータリンク層-LAN接続ボード(NIC)間通信定義用インタフェース。NetWareは同インタフェースをODI(open datalink interface)とし規定 DHCP, dynamic hosts configuration protocol: DHCP使用マシンにDHCPサーバが自動的にIPアドレスを割り当てユーザが細かくNW設定(ホスト名・IP, ゲートウェイ, DNSサーバーアドレス・サブネットマスク)せず接続・利用 → IPアドレス固定静的割付方法(従来接続)よりIPアドレス有効活用可。常時接続ホストに向かないが、ノートPC等ではDHCPサービス利用すべき。ただし、DHCP接続は接続毎に割り当てられるIPアドレスとホスト名異なる Ex. Win: 「TCP/IPのプロパティ」→ 「IPアドレスを自動的に取得」だけ ARP, Address Resolution Protocol: IPアドレス → MACアドレス調べる RARP, Reverse ARP: MACアドレス → IPアドレス調べる ローカルエリアネットワーク(LAN)と広域ネットワーク(WAN)LAN (local area network): 1組織内部で局所的NWを構成したもの規模 = 1部屋-1キャンパス全体位 → コンピュータ間距離近く高速通信可
WAN: LANより広範囲ネットワーク (LANより低速)
遠隔コンピュータ接続可能仮想端末サービス → 遠距離通信・共同作業 NW層レベルを見るためデータリンクが異なるLAN間でもデータ交換できる。IP(internet protocol)アドレスのようなNWアドレス識別を行い、最適経路選択を行い、指定IPアドレスをもつパケットのみを指定された相手先に伝送し、セキュリティ管理やセグメントでのトラブルの波及防止が可能となる Q WAN等による遠所コンピュータ使用理由を列挙せよ インターネット (ネット, internet, net)1970年代(米国): ARPANETと呼ぶNW
機能 1) 情報転送経路障害時も障害回避し別転送経路に自動切替え. 2) 大データを分割発信し受信側で元データに復元
ARPANET開発技術: NW間が直接は未接続でも幾つかのNWを介し通信可能 = 全マシンが相互通信 ⇒ |
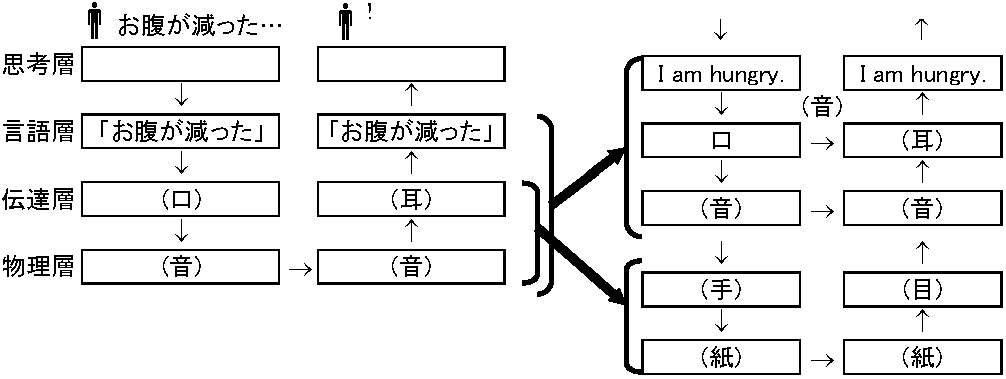
(サービス)プロバイダ (service) provider, IPS internet service provider: Internet接続通信回線を提供する業者 Internetサービス利用にはTCP/IPプロトコルを用いInternet回線へ接続する。接続方法に直接ネットをつなぐ専用線接続と、電話回線経由によるダイヤルアップIP接続の2通りあり、普通業者は両方を手がける 通信プロトコル(規約)通信規約(通信プロトコル): ネットで正確に情報を伝えるための取り決め「サーバ同士がネット接続されても、情報形式異なると情報交流は出来ない問題」回避に、NICが管理流通するRFC規約がある。ネット情報流通にはRFC規約に基づく使用の必要がある。現在、殆どのコンピュータがRFCに従い通信し、W³もRFCやRFC指定の他規約文書等で、特定サーバを選び情報収集する方法、情報蓄積する場合の形式・文法等が定められる。NW初期には、研究施設・コンピュータメーカが独自規約NWを作り、異なるメーカのコンピュータ間接続が困難だった プロトコル階層通信プロトコルは、複数階層に分かれる。ケーブル間接続には、コネクタ形規格や信号signal電流電圧規格決める。別に、情報送受信規格や、W³やemailではURLやアドレス指定方法規格が必要である。これらを一緒に扱うのは無理なため、プロトコル全体を複数レベルに分け(プロトコル階層)扱う。プロトコル階層構造をコミニュケーションに当てはめると(図1.14)、AがBに情報を伝えるのが、最上位階層(思考層)で、次に情報伝達を日本語で行なう(言語層)が、相手に伝えるには口に出し喋る必要があり(伝達層)、喋った言葉は空気振動になり相手に伝わる(物理層)。上位プロトコルが使える限り、下位プロトコル群を替えても同じ様に通信ができる。Ex. 英語でもよく、音が伝わらない時は紙に文字を書き示せば同じことが伝わる。通信プロトコルも同様に、上位プロトコルが同じなら下位プロトコル(通信媒体等)を取替えても正常通信できる
状態遷移: プロトコル理解上で役立つもう1つの概念 電話を掛けるには、電話器を取り、ダイヤルしベルが鳴り、相手が出るとつながる。相手が受話器を置くと、他方は「切れた」状態になり断続音が出る。掛けた時に話し中の時も同じ音がする。どちらでも受話器を置くと、例えば、こちらが先に切れば最初に戻る(相手側に断続音が出るが、こちらには分からない)。状態遷移図で書くと理解し易い。状態遷移図は、個々の状態を□、○、[ ]等で表し、どの場合にどの状態からどの状態に移るかを矢線で表す。最初どの状態にいるかは外から入って来る矢線で明示する。NWプロトコルでも、どう通信を始め、どう通信を終えるかを状態遷移図で考えられる
→ 初期状態→[受話器取る]→発信者→[ダイアルする]→ベルが鳴る Q 1) 前問プロトコルを、カタカナも送れるよう直せ。(ヒント: どの文字でもない組合せを2つ用意し「これから片仮名状態」「これから平仮名状態」という状態切り替えを行う) 2) ビデオ録画予約の流れを状態遷移図で表せ サーバとクライアントプロトコル階層最上位に、個々のAPに対応した応用層がある。一般プログラムでは、APは個々に単独動作できるが、NWを使うAPは、プログラム同士が通信するため共通プロトコルが必要である。応用層では概ね、1プロトコルが1情報サービス(emailやW³等)に対応するサーバ server: サービス提供のためコンピュータとその上で常時動作するプログラム Ex. Webサーバ ⇔ クライアント client: サーバと通信しサービス利用する利用者側コンピュータとプログラム。Ex. Webブラウザ
_________→転送要求→________________________→情報公開→_________ Q 社会にもサーバ-クライアント関係が多数存在する。列挙せよ。Ex. 商店 = サーバ、顧客 = クライアント クッキー(cookie, cookies): PCにサーバから「前回アクセス時刻」等、ブラウザ固有情報を保存する仕組 全アクセス情報のサーバ保存はサーバに負担がかかり、PCに保存し必要時に取り出せた方が便利である。クッキーは有効期限があり、サーバが「○○まで保存」とPCに記録し有効期限が切れれば自動削除する セキュリティ securityNW上の漏洩・侵入・破壊・改変を未然に防ぐ対策クラッキング: NW上で、情報が使用者の意図しない所まで配られたり、他人のコンピュータに侵入し情報を盗み出したり、コンピュータ上の情報を破壊する(犯罪)行為 → NW情報中継中に改変される等、情報の信頼性に問題生じる CUG, closed user group: network内アクセス可能ユーザを限定した部分VPN, virtual private network: internetを企業内専用線NWの様に運用する方法。通常、fireWallやPPTPを使用し、外部アクセスをガードしセキュリティ強化 ファイアウォール firewall: ファイアウォール内側コンピュータをCUGとするNW構成方法で、ハード・ソフト両方用い構築。内外間に境界形成し、内部アクセスに安全なサブネットを形成し外部アクセスを遮断し資源共有する。ファイアウォール頂上1台(top)が内外両方にアクセスするよう設定し、topはインターネットと直接通信を行うので外部不正アクセスに対し厳重なセキュリティ処置必要である。不正侵入の危険を減らす反面、外部情報アクセス制限されたり、特別なソフトウェアが必要となる。ファイアウォール内外部両側から情報をアクセスできるようプロクシ(とSOCKS又はその一方)を使用し設定 プロキシとソックスSOCKSは内からインターネットアクセスを可能にする プロキシ(代理) proxyサーバは、ファイアウォールソフトウェアと共に実行される。クライアント-サーバ間に入り、クライアントの代わりに要求出し、サーバの代わりに返答する。NW遮断タイプのファイアウォール上で稼働させ、ファイアウォールを跨ぐ通信が可能となる。Telnet、FTP等、サービス毎に固有プロキシがある。プロキシは、キャッシュ機構、ログ機構、アクセス制御機構等の面でSOCKSより優れる。SOCKSソフトウェアは、ファイアウォール上か内部サーバに導入する。内は、インターネットアクセスにクライアントとしてSOCKSサーバにアクセスする。Macintosh, UNIXではプロクシパネルでSOCKSホスト(サーバ)名とポート番号を、WindowsはSOCKSホストをINIファイルに [Services] SOCKS_Server=mysocks.domain.comと指定する Q 声出さず(1)隣室, (2)隣家との会話方法考え、問題点を予想せよ SMTP, simple mail transfer protocol (RFC821): インターネット標準メール転送プロトコル。メールサーバ間メール転送、クライアントからサーバにメールを送る際等に使用 MTA, message transfer agent(メイル転送プログラム): ホスト間メール転送(リモート配送)を受け持ち、メールをmailboxに配送(ローカル配送)する。転送プログラム起動もする リモート転送: メール表書通りに配送(返送)する。宛先ドメイン部からDomain Name Server (DNS)のMXレコードを検索し宛先(送先)ホスト決定し送先ホストとの接続手順にSMTPを使い配送する MUA, mail user agentメイラ: 利用者がメール読み書きに使う。mailboxに配られたメールを読み出し、書く手助け、MTAに渡したりする。mailboxを直接読むのではなくPOPやIMAPプロトコル使いリモートのメイルサーバ上のmailboxを読むMUAもある mailbox: 受信メイルのMTAによるローカル保存場所。mbox形式、maildir形式等がある Mbox: メイル0個以上含むファイル。メール配送中クラッシュ等で信頼性低。mboxファイルやmhフォルダではメッセージ契れ次メッセージとつながりMTAは再送を試みるが破壊メッセージが表示される。プログラムが使うロック方式が違うとファイルは破壊される。多くのサイトがSun NFS (Network Failure System)以外ないため使っているがNFSにより問題悪化し、信頼できるロックがない。2マシンで同じユーザ宛メイルを配ろうとしたり、メイル配送を受け持つマシン以外で利用者がメイルを読むと利用者メイルが失われる危険がある Maildir: メイル受信用ディレクトリ構造 信頼性: 1. 個々のメッセージは配送終了時点で処理終了し他と独立. 2. 配送プロセス毎に異なるファイルを使いロック不要<. 3. 配送メッセージはメイルリーダが書き換えても削除しても安全. 4. NFSでも問題なく動く ポストオフィスPostOffice: 例えれば電子メール上の郵便局で、配信時、一時的にmail保存し、使用するメンバ管理等行う。大規模なmailになると複数になりPostOffice間をMTAによる中継が必要 |
|
コンピュータ情報取り扱いでも、テキスト情報が多い。W³は画像・動画・音等様々な情報を含められるが、情報伝達方法はテキスト情報が中心となる。テキストの弱点は、構造が1次元で思考中は多事柄が網目状に繋がっても「1つずつ順番に」書くことがある。情報技術は、その不自由さを減らす手段として有効である。Ex. W³ハイパーテキスト Q 人の主要情報伝達手段の1つである発話(声に出して喋る事)とテキストを比較し、長所、短所を比較せよ タッチタイピング: キーボード見ず「そらで」キーを打つこと
標準キーボードホームポジションは、左手「ASDF」右手「JKL;」に置く
明日は、なんと、学校が、休みだ。 ←←← 挿入 ← [ 学校が ] 保管場所 同一名ファイルに保存 = 上書き = 古いファイル消える → 重要情報に上書きしない (上書保存時は「OK?」等と注意を促すエディタもある) ファイル file: コンピュータ中の情報に名前つけ保存したもの = ハードディスク等媒体に作成される論理的データ保管部分 = データをある規則に従い保存し、参照できるようにした1つのまとまり メモ ファイル保存: エディタ側「ファイルに書出す」 = ファイル側「ファイルに書込む」。ファイル読出し: ファイル側「読出し」 = エディタ「読込み」 → どちらの言い方もよく使う
┏━━━━━━━━>💻 編集 → 「開く」 名入力/一覧から選択 保存 → 「名前をつけて保存」元ファイル保存 → 「上書き保存」(名前指定不要) 重要ファイル上書きに注意 情報処理 = 整理手段重要Ex. ファイル分類一覧を行なうプログラム → ディレクトリ: この分類単位のことディレクトリ中に更にディレクトリを置き階層構造分類も可。ディレクトリ作成・削除、ファイルをディレクトリ間移動等のプログラムが必要となる。システムにより、ディレクトリ操作プログラムとファイル一覧表示プログラムが一体になっている。エディタでのファイル読み書き機能に前記の機能が付属することもある
テキスト置換: テキスト情報中の特定文字列を、別の文字列で置き換える 置換: 一括置換と逐次置換があり、「影響が及ぶ」という意味の「及」は漢字、「AおよびB」は平仮名にしたければ置換を一気に行わず1箇所ずつチェックできる。目では、見落としや間違いが避けられないが、検索置換では心配が減り、単純繰り返し作業はコンピュータに適する 電子メール (email, e-mail)NWを通じある人から別の人宛にメッセージを届ける情報サービス概念: 電子情報NW上サービスで、古くからあるのが電子メール (email, electronic mail, e-mail)である。emailは、電子的にメッセージを届ける情報サービスで「電子の葉書」と言える。情報を、コンピュータ利用者に知らせる仕組みで、その内容がemail(「電子郵便」ではない)である。email送受信に、利用者は「メアド(メールアドレス, e-mail address)」をつけ、手元のコンピュータからインターネット接続されたメールサーバに送る。メールサーバは、メール宛先を解釈し、受取人のメールサーバにメール転送する。受取人は自分のメールサーバにアクセスし自分宛メールを取り出す
• 遠隔地へ迅速に送受信 • 多数宛同時送信 • データ送信に利用 emailは未着、中継点サーバ管理者閲覧可能性あり、封書書留より「葉書」的なので、隠すべき内容は暗号機能使い、返信を送る等の配慮を忘れないS/MIME, secure multipurpose internet mail extentionはRSA Raboratories等策定MIME形式メール暗号化形式。本来128bit鍵使用だが、米国輸出規制で米国以外は40 bit鍵まで利用可。PGP, pretty good privacyはPhilip Zimmermann氏(1991, 米)が初版開発メール暗号化ソフトで、ソースコード印刷し、輸出規制解除し、海外でも「国際版」とし128bitフル規格を利用可 利用方法利用者認証: 使用者をコンピュータに正しく識別させること必ず始めにコンピュータに「使用者」を教える。典型的には1人1人が固有ユーザIDを持ち、他人が利用しないようパスワード password (PW)設定する。開始時にID/PW入力しコンピュータを使える状態にする ユーザID: 認証のために使う、各人に割り当てた他の人と区別のつく名前 login: 利用者名 → Password: _________ → Welcome ... どのemail用クライアントでも、email記事書式はRFC準拠で、原理的にはプロトコルに従うので同じ。クライアント起動すると、自分宛受信メッセージ一覧が表示される(未読のみ一覧表示もある)
04/01 taro@kou.ne.jp 学祭について メッセージ = ヘッダ部分 + 本文: 「ヘッダ」は、宛先、表題、発信人、発信日時等の「メール属性情報」部分。「本体」が本文。ヘッダと本文は分割表示される メールアドレス(メアド), email送信元宛先: RFC書式規約に従い書くだけ。メール受信時は送信メアドで送信者知り、メアドは個人特定に重要な役割 From (発信者): 差出人メアド書く。通常「ログイン名」等からFrom内容を自動判断しe-mail・NN用ソフトがFromヘッダーを自動生成する To (送信相手): 送信先明示ヘッダ。複数人同時送信でも送信者全員分かる CC: 控え(写し, カーボンコピー, carboncopy)送信相手。昔のカーボンコピーで複製残す習慣から。CCは、同内容を複数人に送れemailも採用。CCヘッダは、副宛先送付を表し、返信不要と考えてよい Bcc, blind carbon copy: 非表示宛先、CC送信先隠す時に指定。BCC受取人名は、メッセージヘッダに非記録。BCCだけでメール送信はできない Subject: 件名(表題)。email・記事メッセージにつけた表題で、「必須」ではないがつけるべき。個人的E-mail受信者は件名に関係なく目を通すため表題は日常習慣ではないが、email検索時に適切な件名があると便利である。NNは不特定多数を対象に発言するため、情報交換のために読んでもらうにはSubjectで中身が分かるようにすべき。Subject: questionでは中身が分からない。Subject: What is needed for living in England?なら、知識・興味を持つ人が目を通してくれそうである Date: 発信年日時記録したヘッダ。普通タイムゾーン(TZ)記す。日本正午発信emailがロンドンに直ぐ届いても、現地はAM3:00で(夏時間+1 hr)、多分返事は日本の夕方以降。一方、正午にワシントンに送り直ぐ到着しても、現地は前日PM10:00で、やはり直ぐの返事は期待できない。Dateヘッダは、1) Date: Thu, 05 Mar 1998 00:32:27 +0900 (TZ+0900地域、Ex 日本発メール), 2) Date: Wed, 04 Mar 1998 09:46:19 –0600 (タイムゾーン-0600地域、Ex USAテキサス発email), 3) Date: Wed, 04 Mar 1998 16:49:29 +0100 (タイムゾーン+0100地域、Ex フランス発email)、の様に書かれる。最初のemailが木曜日発信で、次の2通が水曜日発信のemailだが、時間経過をタイムゾーンと日付変更線を含め考えれば、日本からのemailが一番古い。国内タイムゾーンは、他にThu, 05 Mar 1998 00:32:27 GMT+0900, Thu, 05 Mar 1998 00:32:27 JST等の書き方がある タイムゾーン: グリニッジ天文台南中時刻を正午とする「世界標準時GMT」に対し、各国・地域標準時の差を表したもの。日本はGMT + 9時間] → 季節差注意 (Ex. 北半球 = 夏 → 南半球 = 冬) Message-ID: 各メッセージ固有識別記号 - メッセージ管理に自動付与 Ex. <199802140922.SAA27599@wise19.abc.def.ghi.jk>: email転送時は、これらヘッダの他に、転送に必要なヘッダが付加され転送途中の中継点の記録も次々にヘッダに付加される 電子メール送信送信先アドレスTo、主題Subject、本文指定すればよい。クライアントによりCCに自分を指定せずとも送信メール写しを自動保管する機能誤送信!: 送信e-mailは取り戻せない。アドレス間違え送ると… 1) 送信先アドレス無効: FromがMailer-Daemon、表題User unknown/Host unknown等のemailがメールサーバから自動的に送られる。その内容から配送失敗原因分かる。「User unknown」 = ドメイン部分正しいが利用者なし。「Host unknown」 = ドメイン部分違う。Ex. tsuyu@abc.def.ghi.jk宛emailは「利用者tsuyuなし(User unknown)」なためemailが戻された 2) 送信先アドレス有効: 他人に送られ絶望。送信正常終了し気づかず、誤配相手から連絡あると判る。誤配先に謝りメール送り、正しい宛先に送り直す 3) アドレスの一部を間違えた: 複数メールアドレスをToやCcに列挙し、一部に誤ったメールアドレスがあると面倒である。正常受信者が返事を書くと、大抵、元メールのTo, CcのメールアドレスがCcに付加され、それにも間違ったメールアドレスが含まれる。その間違ったメールアドレスが無効な場合、返事を書いた人にmailer-daemonからエラー通知が届き、間違ったメールアドレスが有効な場合には誤配となる。早く、To, Cc全員に訂正情報を流す |
返信・反応emailへ返答・回答・意見・反論といった「反応」を行なう(リプライ、フォローアップ)際、「どのemail・記事の」「どの部分に対する」反応かを示すべき。反応を読む人が使うemailクライアントソフトのために、ヘッダ使いMessage-ID示し、更に、読む人のために参照・引用を行なうべき返事もemailとするのが普通。「返信」機能使うと、自動で送先等設定され、元メッセージが引用される等、返信に便利 「>」は元のメッセージの引用部 - 不要箇所削除し必要箇所引用も大切 返信の約束ごとSubject文字列先頭に"Re:"つけ、元メッセージへの応答を表す慣習がある 返答Subjectは、「Subject: Re: xxxx」とする。返信内容が元表題から外れるなら「Subject: yyyy (Re: xxxx)」等とすると読む人に親切 メモ: 返信主題を元主題前に英語ビジネスレター慣習由来のRe:「について」をつける(辞書!)。「Re:」をreply, response省略形と勘違いしたり、「レス」と略すと、話が通じない
メール到着 Q メールをフォルダに整理せよ。整理方針を複数考え、最も良い方針を選べ ネットニュース(NN)多数ニュース群から成り、1群に記事投稿すると、記事配送され、興味を持つ人が記事を読める情報サービスインターネット多対多で文字使用情報流通にNNがあるが、報道ではなく利用者が意見表明・議論・教示する「共同掲示版」である。利用者はNN記事にNewsgroups名つけ、自分のコンピュータからニュースサーバに送る。世界中のニュースサーバ間では手持記事のやりとりをし、異なる組織にいる人同士で記事交換出来る。NNは、emailほどではないが古くからある情報サービスで、起源は米国USENETという低速NWである。USENETはNNが代表的サービスの1つ(もう1つがemail)で、NNをUSENETと呼ぶことがある。投稿は世界中に配送され多数の人が読める。email同様、NNでも投稿に対し追加投稿(フォローアップ)できるが、多数の人が投稿し全記事一緒くたでは(1日数万メッセージ配信)混乱するため、NN記事は話題別ニュースグループに分かれ、利用者は適切な(興味/話題)群を選び記事投稿したり読んだりする。emailが「葉書」なら、NNは(一群の)「掲示板」や「新聞」に相当する トップカテゴリNNは、話題別Newsgroup作り、興味を持つ人達がNewsgroupに投稿し情報交換成立 - ニュース群名は、fj.rec.sports.baseballと「.」で名前を区切る形となる。一番右側(baseball)が個々の群を表し、その左側(fj、rec、sports)は幾つかの群をまとめカテゴリ(分類)という。一番左側の名前(トップカテゴリ)毎に、ニュース群の管理・配送方法変わる
代表的カテゴリ: カテゴリとニュースグループ(群)トップカテゴリ下の群構成やその意味、使われ方は、カテゴリ毎に違う。NNでは、W3等と違い複数のやり方の分類が共存できず、分類変更も簡単にはできないので興味ある群を探すのはやや大変メモ fjは「From Japan」(日本発信)で、「For Japanese」(日本語/日本人専用)ではない fjの構成例(「*」は「-以下」を表す) fj.comp.*: コンピュータ, fj.sci.*: 科学, fj.soc.*: 社会, fj.rec.*: 趣味娯楽, fj.rec.autos: 車, fj.rec.autos.sports: 4輪モーター, fj.rec.misc: その他 → fj.rec.autosは単独群かつカテゴリを兼ねる。「娯楽全般」は、fj.rec群ではなく、fj.rec.misc群がある(miscはmiscellaneous) 記事を読むNNでも、具体的操作はクライアント毎に変わり、カテゴリも違う。想像上のカテゴリ「kou.*」を読む場合の動作を見る。ブラウザ起動で、ニュース群一覧が表示される。各群が1行に表示され、その群の未読記事数が群名の前に表示される。多くのNNクライアントは、未読記事個数0群の一覧(非)表示モードを切替えられる。既読記事は一覧表示しないクライアントもある。マウス等でニュース群を指定すると、その群の投稿記事一覧画面に切り替わる。ニュースクライアントにより、特定群の記事一覧画面から始まるものもある
3: kou.general
2: kou.kamoku.butsuri
4: kou.kamoku.suugaku
1: kou.test
R 2418: [sensei@kou.ne.jp] schedule on tomorrow NNは世界中から刻々と新しい記事が送られるため、コンピュータ機能で未既読を管理し、同記事を何度も読む、重要な記事を読み落すことを防いでいる 記事投稿NN記事投稿はemail送信に似るが、送信先To:ではなくニュース群名Newsgroups:と主題Subject:を指定する。多くのNNクライアントで、記事一覧画面で「投稿」選択だけで自動的に群名に見ている群を設定してくれる既にある記事を引用し投稿するには記事を指定しクライアントの「フォローアップ」機能を選択する。いずれも送信者や日付やメッセージIDの情報が記入されないが、これらはNNクライアントが自動的につける。これらを投稿し終ったあとの記事一覧画面を見よう。ただし、記事が伝わるには遅れがあるため、ニュースサーバが違えば記事や記事番号も違う。記事一覧画面は誰がみても(既読情報を除けば)同じであり、ある人が投稿した記事を誰でも読める メーリングリスト(mailing list, ML)NW管理者が設定用意し、その宛先にemail送ると群全員に配信される。群は、数人から世界規模まで様々。MLを使えば、NNと違う形で、多対多情報交換が出来る。MLは、公開と参加者以外非公開がある。公開MLも、新規参加を、歓迎から紹介者必要まである。emailは基本的に私信だが、MLは、私信と言えず情報取扱・発言に私信・公開両面を考える必要があるメモ 「旅行情報交換」メールアドレス一覧をメールサーバ登録し、リスト全体名にtravel@abc.def.ghi.jkとメールアドレス設定するとTo: travel@abc.def.ghi.jkで送られたemailは、その群のメンバー全員に配布される Q 公開のMLメッセージを見てみよ。そこからMLとNNの違い考えよ サーバ管理(不正侵入防止)パスワードのつけ方(時々変更すると盗まれる可能性減少): 簡単に解読可能なもの避ける + メモは見られる恐れEx. [単語 + 数字] / 複数単語先頭部分取出し → 推察されにくい規則によりより安全なパスワードとなる サービス: 必要サービスのみ提供し、サービス使用可能クライアントを必要範囲にしセキュリティーを高める
鍵データ長56 bit、ブロック長64 bit。56 bitは約1017の組合せだが、総当たり法で解読可能 鍵データ長128 bit、ブロック長128/192/256からの選択がNISTの要求仕様。15方式が候補に提案され、IBM MARS、RSA Raboratories RC6の2つが最有力候補となりNTT E2が追う状況だった デーモン daemon: ファイルシステム障害常時監視プログラム最新な少セキュリティホール版に常時更新
Web-BBSBBS, Bulletin Board System: 電子掲示板システム。PC通信の同義語として使用されることもあるW³情報公開機能に、掲示版機能をつけたのがWeb-BBSである。Webページ内に掲示版を作り、閲覧者は誰でも閲覧、書込み、できる。Web-BBSは、誰でもその情報を入手でき私信より公開された通信とし扱われ、プライベート情報書き込み等の知的所有権やプライバシー保護問題を生じさせがちで注意が必要である Q 既公開Web-BBSを見物し、NN, MLとの違いを、表に追加してまとめよ インターネットでの情報流通インターネットを使った情報流通のあるべき姿インターネットメッセージ: W3内容(コンテンツ)、e-mail, NN記事等全て 情報流通方向性 → 発信・受信情報が誰から誰に発信されたか把握大切 インターネット利用者 = 情報受信者と同時に情報発信者 新聞・放送等マスメディアと同じ立場に立ち、発信の責任自覚必要 e-mail, NN: 同様問題発生 → 反応直接、発信者に届くW³: 作成コンテンツに対する反応が直接的に得難く、周囲の指摘で適切な使い方を身につけること困難 Webページに掲示版機能等 → コメントもらうと反応得やすい 情報流通方向W³: Web fileはサーバ記憶 → 閲覧者はサーバに内容要求 → サーバは転送Web閲覧者はemail等用い作成者に連絡 → 作成者はWebページ改訂 W3はNN同様1対多数情報交換だが、NNと異なり文字以外の情報流通可 Web話題は作成者決定 → ページ話題別分類不可 ≠ 「共同掲示版」, NN |
|
過程(プロセス) process: 背景情報や各知識を関連づけつつ解決図る Ex. 創造活動 → 新アイデア誕生過程 , 問題解決 → 分析・改善過程 「問題」内容は多様で、解析的に解けないことや複数解のことも。複雑な問題の抽象化細分化により問題を明確にし、解決へのコンピュータ活用法を考える。内容は、問題発見(問題把握、観察情報収集)、問題分析(文章情報整理、モデル化とアルゴリズム)、問題抽出(目標設定、モデル作成)、問題解決(シミュレーション、待ち行列、数値的モデル、数値計算)等 アルゴリズムが分かれば、プログラム作成、APソフトウェア活用、具体的問題解の獲得ができる。その後、得た結果が目的物かを評価する作業があり、評価は、多データの組合せでどの位機能するかを調べる作業である。無限データテストは不可能なため、選択的テストが行われる実体 entity: 対象の仕組に関係する人や物等を抽象化し捉えたもの。Ex. 学校そのもの ≠ 実体 = 学校名、所在地、学級名等の属性を取出しまとめたもの プロセス(過程) process: データ処理(中)のこと → 実行状態にあるプログラム。TaskとThreadの総称 タスク task: 実行状態のプログラム。状態情報を完全に持ちコンピュータ内で独自に動く (≈ プロセス) 例題. 陸上競技大会を開催したい: 「企画運営を小人数で効率よく行なう」目標が掲げられた。ありそうな問題を調べ、事前に解決方法を考えた(催し企画問題)。早速催し企画問題に取組むことになり、準備委員会で発言を得た。()内は整理用キーワード、[]内は参照記号 発言内容 会費は幾ら(収入/人)[a] 会計係が必要(人/作業)[b] まず予算を立てるべき(収入/支出/人/物)[c] どんな経費があるか(支出/人/物/作業)[d] 当日アルバイト代は幾ら(人/支出)[e] アルバイトは何人必要(人/作業/支出)[f] 大会案内状発送は何時できる(作業/人/支出)[g] 名簿は(作業/人)[h] 参加校名簿は去年のを使うが、選手・関係者名簿を作成せねば(作業/人)[i] 会場略図も必要だ(作業)[j] 会場迄の道順、バスダイヤも用意せねば(作業)[k] グラウンドや会場の整備も必要だ(人/作業)[l] 大会終了後、記録等報告書作成が必要だ(作業/後日)[m] 競技記録記述方式を決めると整理に便利?(作業)[n] 発言を、キーワード整理すると、経費関連問題、運営問題、報告書作成問題に分かれる。「収入」と「支出」をキーワードに選ばれた項目a c d e f gを経営問題とし、「作業」に関する項目b d f g h i j k l m nを運営問題とした。「後日」に関する項目mを報告書作成問題とし別群とした コンピュータ利用: 利用者からみたコンピュータによる演算処理利用目的 演算処理: 科学技術計算、大量データ統計計算、論理演算、文字列処理、画像処理等 情報蓄積と検索: 文献情報、事実情報等を蓄積し必要時に情報を取出す処理。Ex. DB シミュレーション: 理論実証、仮説検証、あるいは設計制御のために行う模擬実験等 事務処理: 販売在庫管理、給与計算、原価計算等の業務を支援する様々な処理 文書処理: 文書の作成や清書、機械翻訳等 コミュニケーション支援: emailやファイルによる情報交換、マルチメディアプレゼン等 機器制御: 航空機自動運転、ロボット製造工程制御、鉄道運行管理、エレベータ制御等 問題分析解決: 複数処理組合わせ、速く、広く、正確な処理が要求され、そのためのソフトウェアも開発される。しかし、現実問題は複雑でコンピュータ活用には、自らプログラム開発することも多い 数値データ処理プログラミング programming: 問題の抽象モデルを作成しアルゴリズムを考え、コンピュータ言語で表現することアルゴリズム algorithm: データ構造に基づき有限時間内に問題解決するよう、入力データ、演算処理手続、出力結果を、表現記述した手続き → データ構造 + アルゴリズム = プログラム (Wirth パスカル開発者 1992) 数値データ入手し、大量データ処理や演算処理をする。数値データを加工し状況が見えることもある。少データ量で簡単な計算なら人手処理可能だが、ミスを犯し計算も遅く、繰返し処理はコンピュータが優れる。プログラミングによりコンピュータ処理が行え、自動化が実現できる。プログラミング内容は、解決問題モデル化/アルゴリズム作成/プログラム作成/プログラム動作確認、が含まれる。問題分析重要工程はモデル化とアルゴリズム作成である。処理作業を記述すると、幾つかの演算に分解でき、これらの演算種類を基本演算命令と呼び、基本演算命令を組合わせコンピュータに記憶させれば迅速正確に演算処理を行う 問題のモデル化とアルゴリズムコンピュータ利用問題解決は、問題モデル化、意味明確化が重要でモデルは1つとは限らない。モデル化に必要な点に、1 = データ正確再現, 2 = 簡単, 3 = 他データに汎用的に追従可能 がある。モデル化のできは、プログラミング工程に大きな影響を与え重要作業Def. モデル化 modeling: 抽象化により問題の本質を明確にすること
A. 「できない」。ある点から出発し一筆書き可能かと言う問題に帰着でき、現実問題が抽象化されモデルを描く。数学問題は抽象化が多く、現実問題をモデル化したものともいえる Pr. 1 橋を渡る最大パターン 7! = 5040通り → 全部調べる(PC使用) Pr. 2 Eulerの数理的証明(オイラー路) ☛ グラフ理論 graph theory 問題抽出目標設定問題解決には、何をどこまで解決するかという具体的目標値必要Ex. 「催し企画問題」: どのような問題が設定できるか。発言事項をまとめ解決せねばならない問題をパターン毎に整理すると、経費問題2、運営問題6、報告書問題1つあり、問題の要点は以下の様に記述できる 経費問題
モデル作成関係者間情報や作成データ相互関連(図2.7)等、多問題を含む時に全体図示化は理解を助けるQ 新聞作成の作業分担を考えると、どのような係が必要になるか。係間で情報はどのように流れるかを図示せ。新聞作成で収集する情報源(データ実体)と情報の活用プロセスの関係をデータフロー図で示せ
░░░░░░░░░参加者░░░░░░░░░
参加者名簿───────会 計 情 報─────┐
│ └歴代大会*の資料┘ │ 手伝要員名簿
│ │ 本部要員名簿─────┘
│ └───┐ │
└─────────情 報───広報
運営計画 一般
図. データ相互関連。枠: データモデル。線: データ同士が直接関係する。参加者名簿: 個人コード、参加者氏名、所属学校名、参加競技番号で構成。他名簿: 氏名、所属、住所、電話番号で構成。会計情報: 参加費、補助金等の入金データの他、使用料、人件費、印刷費、郵送料等基本データ表を含む。歴代大会資料: 第1回大会からの報告書綴り。運営計画情報: 大会当日競技進行プログラム、担当者一覧、競技記録記入表、要員配置表、会場整備図面等。*: 長期保存資料。無印: 本大会期間のみ保管データ
[ 本部要員名 ]┌[歴代大会資料]────┐ [ 1: 本部 ] │ ┌───┘ │ [参加者名簿作成] │ │ ┌──[手伝要員名簿]──┐ │ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ┌[ 参加者名簿 ]→[ 2:本部 ]→[ 担当者一覧 ] [ 3: 本部 ] │ ↑↓ [ 運営日程決定 ]────┐ [運営予算作成] │[ 4: 受付係 ] ↓ ↓ │[参加者出席確認]←[競技進行プログラム] [運営計画情報] [ 会計情報 ] │[資料渡す ] ↓ │ ↓ ├────────→[ 6: 実行委員会 ] └───→[ 5: 広報係 ] │[ 記録一覧 ]←[競技進行・結果記録] [ 案内書作成 ] │ ↓ └───────────────────────────→[ 報告書作成 ]図. 催し企画(大会関係者-資料活用関係)データフロー。□: データ実体。中線入枠: 線上側にプロセス(過程)番号と担当部署、下側にプロセス記す。過程から出る矢印: 処理により得られたデータを格納していること。過程に入る矢印: データ利用すること。Ex. 過程6の実行委員は、競技進行プログラムと参加者名簿を利用し競技進行し、成績を記録一覧に記述する。参加名簿というデータ実体は、過程1で本部で作成され、過程2, 4, 5, 6で利用される。無入力矢印のデータ実体は、既存の実体である 問題解決(プログラム開発)= プログラミング言語 + 編集用エディタ + 管理ソフトウェア(試験、バグ検出)問題がモデル化できれば、プログラム開発せず、ワードプロセッサ、描画・表計算・プレゼンツール、DB、ブラウザ等既存ソフトで処理も可能。ただし、コンピュータに、良いモデルとアルゴリズムを与えなければ正しい結果得られない [手作業 ↔ コンピュータ]の計算処理上の違いは:
シミュレーションと確率モデル現象に直接触れない実験にコンピュータシミュレーション(模擬計算) computer simulationが便利であるEx. 交差点信号: 交差点に行かず自動車の流れを最適にする信号点滅間隔をシミュレーションで現場信号点滅と殆ど同じ状況を作り出し決める |
シミュレーションでは、道路、交差点、信号機、自動車等のような対象物を確率変数 probability variableを利用しモデル操作をする。実際の確率変数が得られなければ乱数を使い確率変数の近似値を求める
数値的モデル数値処理: 判断や繰返し必要条件を組合わせた処理存在 Ex. 催し企画問題
876 |54 |3 |21 個人コードデータの学校別コード(4-5桁)を抽出し同じコードをまとめると配布先を群化でき、この問題は以下の桁抽出モデルとして一般化できる 桁抽出モデル「n桁整数特定j桁分抽出」問題のモデルで、特定数桁を残し他を削除するアルゴリズムを考える。与えられた整数値d、整数値桁数n、抽出範囲i桁目からj桁分とおき、抽出データrを求めるアルゴリズムを2通り示す
Ex. 1: 上位桁を始めに削除 Q 経費の見積: 経費問題2は、単価表をもとに以下5項目を積算、予算を見積もることであった。1)人件費, 2)会場費, 3)郵送費, 4)印刷費, 5)その他: 機材の借用費、運搬費、ゼッケン等。各項目毎の計算アルゴリズムを考えよ (1) 人件費計算 Q: 参加者50人につき1人の割合で手伝い要員をおき、参加者に端数がある場合には1人追加するものとする。手伝い要員の人件費を1人当たり8000円とすると人件費はいくらになるか。参加者数を与えて計算せよ n参加者数、k群人数、c手伝要員1人当たり人件費ならば「nとkを与え、nをkづつの群に分け、端数を別途1群とし、群数gを求める。データcを与えc × g (人件費合計) を求める」モデルで示される
アルゴリズム (2)会場費計算 Q: グラウンド使用料 = 一括5万円。参加者控室 = 100人収容可能部屋3 + 60人部屋5 + 30人部屋5予約可能。使用料 = 100人部屋1.8万, 60人部屋1.2万, 30人部屋0.7万円。参加者数に合わせ最も安価な使用料計画作成 → 参加者数与え表を完成する問題 参加者数x、部屋種類k、収容人数ni、空部屋数fi、使用料単価pi、予約数mi、使用料siとおき、問題解決流れ図を示す。添字のiは1, 2, 3, …, kと変化する (問ではグラウンドがk番目の部屋に相当)
4枠アルゴリズム
1枠アルゴリズム 1. i = 1とする 2. miに0を代入 3. siに0を代入 4. i + 1をiに代入 5. i < k → Step 2へ 6. 終わり
5枠アルゴリズム 3枠アルゴリズム 1. x, k, ni, fi, piを与える 2. i = 1とし、xをyに代入 3. y/niの商をmiに代入 4. y/niの剰余をrに代入 5. mi – fiをtに代入 6. t > 0ならfiをmIに代入し、 ni × tをrに加算しStep 10へ 7. t = 0ならStep 10へ 8. i = k – 1ならStep 12へ 9. r > ni + 1ならmiに1を加算して使用料の合計計算へ 10. r = 0なら使用料の合計計算へ 11. i < kならiを1増やし、rをyに代入してStep 3へ (始め) 1. [収容可能な人数を計算しcとする] → <cとxを比較>
x < c → 2. [miとsiを0とする] → 3. [部屋の予約数を計算する] → 5 Yes → end or No → 4
4. [fiをmiに代入する] 5. [使用料の計算をする] → /結果を表示する/ (終わり) 図 流れ図 (3) 郵送費計算Q: 学校毎配布資料1部250 g以下、個人毎配布資料1部25 g以下。資料を一括し学校郵送時に通信費上限は幾らか。参加校30校以内で、一校当り参加者は最大15名とする。(解) 25 g × 15 + 250 g = 625 g、1 kg 以内で一校当り最大郵送料700円。通信費上限700 × 30=21000円。この料金計算アルゴリズムを作れ
表 郵便料金表 (5)その他: 機材借用費と運搬費等は計5.5万円、ゼッケンは選手1人1000円以内とする(選手数 < 参加者数) Q 各学校参加者数を与え、通信費と印刷費を計算するモデルを考えアルゴリズムを示せ Q 項目1-5までの経費を効率よく計算する手順を流れ図で示せ (ヒント: 各項目処理をまとめ、共通データを一度だけ入力し、複数項目で共用を考える) アルゴリズム問題意味明確 → アルゴリズム作成可能: 一意的に解決できなければならず、記述は有限で、実行時間も有限
アルゴリズム: 一般に定義域(入力)と値域(出力)が定められ、入力0個以上、出力1個以上が与えられる 1. 定義域-値域の関数性 2. 解釈一意性 3. 記述有限性 4. 時間有限性 よいアルゴリズム = 実行時間と占有記憶量両面で効率よいエンドユーザコンピューティング (End user computing, EUC): 利用者自らプログラミングせず問題解決できること
Ex. APソフト
Ex. 数値処理(R): 高使用アルゴリズムはライブラリー利用 動的リンクライブラリ DLL, dinamic link library: プログラム本体と別にあり、実行時に動的に接続するライブラリ 利点: 複数プログラムが同機能使用 → 全プログラムに同じライブラリ使え、資源節約でき、ライブラリさえ差し替えれば全プログラムが修正される(DLL - Windows) ↔ 静的リンクライブラリstatic link library 分割アルゴリズム partitioning algorithm 例題 植物Aは生育2年目以降、毎年株分けできる。2年経った株を毎年株分した時の株の増え方はどうか
1(年後) 2
3
4
5
6 この植物が、n年後にtk株になれば株数はt1 = 1, t2 = 1, t3 = 2, t4 = 3, t5 = 5, t6 = 8 … の数列で表せ(図2.3)、t1 = 1, t2 = 1, tk = tk-1 + tk-2で定義できる(k = 3 … n) (フィボナッチ数列) Q. フィボナッチ数列の各項求めるアルゴリズムを示し10年後の株数を求めよ
( ) 端子: 始めと終わり | [ t1 = t2 = 1, k = 3とおく ] | _____________/ Nを与える / | no [ tk-1 + tk+2をtkに代入する ] ┏━━━━━━━>| ┃__________[ 1を増やす ] ┃______________| ┗━━━━━ ≪ k > N ≫ | yes [ tkを表示する ] | ( 終わり ) 図 株分け問題流れ図 (流れ図の主な記号 JIS X0121抜粋改変) 1. 直接的方法: 起こりうる全ての場合を調べることが可能な時 a) 解析的に手順決まる時: 最小値、最大値等直接全て解析的に求まる → そのままプログラミング b) 総当り法method of all possible combinations: 全事象を調べる – 力ずくだが、計算回数少ない時は有効 Ex. オードスミス法 Ord-Smith metohd: 組合せ要素数nを与え、n!個全組合わせをアルファベットで作り出す 2. 起こりうる全事象を調べるのが不可能な時: 天文学的組合せ数 → コンピュータでも計算に膨大な費用と時間a) ダイナミックプログラミング dynamics programming Ex. P → Q: n段階を経て移動。各段階はm個の状態があり各段階ではこのどれかの状態となる。i段階のj状態から(i + 1)段階のk状態に移るにはCi(j, k)のコストがかかる。この時P → Q移動の最小コストを探す
〇
〇 m
〇
〇
〇 f(i, j)をPからi段階のj状態に行く最小のコストとする |
問題発見から問題把握「問題発見」: 現状の中の問題を見つけ出す ≈ 原因発見「問題把握」: 現象観察 → 情報収集 → 情報整理 → 分析 → 問題抽出 日常は、曖昧な会話で「明日の天気は」と尋ねられても仲間同士なら状況判断し答えられる。挨拶程度の会話なら、いい加減な応答も問題はない。しかし、適切な答えを期待する場合は、場所と時間が限定された質問ではなく、この問いかけに対する答えは難しい 「問題解決」: 数式、社会、友人 … 問題を解決、と曖昧で様々な解釈可能
+ 同一「問題」でもTPOで問題解釈異なる
Ex. 複雑問題解決: 問題状況分析し複数問題に分割 = 個別解を統合し全体の問題を解決する一連の案を示す 多くの情報と解決過程が必要 (Ex. 天気予報 = 多データ + 処理解析方法・手順)。過剰な人為的処理がないよう工夫し、条件を付け曖昧性を排除する。問題解決には、新方法開発も必要だが、既存の方法を応用した解決方法も考え、その際も具体的な状況への当てはめ方を考える Def. モデル model: 現象を定量的に解く数式、ものの見方、捉え方Def. モデル化 modeling: 実世界対象を抽象化し表現 観察と情報収集: 問題把握は仕組・現象観察から始まる。問題状況が何を発しているかに注目し、意識的に情報収集する必要がある。即ち、問題把握は現象の調査分析が前提である。よく使う調査方法として次の5項目をあげる
Q 方法1-5は、どのような問題で役立つか、例をあげ、使える理由を説明せよ Q 交通渋滞で話題の交差点がある。原因究明に最適な調査法とその理由は 資料(情報)偏向
問題分析問題解決方法 ≠ 1つ ⇒ 人間は勝手な規則を与え問題を複雑にしてしまうこともある。調査で得られた情報の本質を理解するため状況整理必要取材学: 探求姿勢と方法論を体系的に捉える ≠ 情報収集技術 (加藤 1975) → 文章情報使う状況整理 |
KJ法(発想整理手法) 開発者川喜田二郎頭文字: 情報をカード記入しキーワードで関連カード分類繰返し状況分析。文章でイメージ湧かなければ図化し直観的理解 手順: 1. データ収集カード化 → 2. 類似カードグループ化 → 3. グループ表札付 → 4. 表札束で2-3を繰返す(配置) → 5. 配置ごと貼付け枠で囲む(図解) → 6. 図解見ながら文書化 KJ法AP: 羅列文系統整理・問題点等抽出 Ex. Miro, Notion, Scrapbox 問題背景や概略を示す略図の他、データ間関係を示す実体関連図(実体間関係表す図)、実体-プロセス関係を示す、即ちデータの流れ処理を示すデータフロー図等がよく使われる。Ex. 陸上競技大会開催という状況設定を通し、問題点を掘り出し状況を分析Def. 社会調査: (1) 社会または社会事象について、(2) 現地調査 field survey により、(3) 統計的推論のための資料を得る (飽戸 1971) 社会調査法 social research methods1) 心理学的実験: 被験者に対する実験によりデータを収集する方法2) 記述・統計データ処理 Ex. アンケート調査法 無作為抽出 ↔ 有意抽出
[条件] 抽出単位を一つずつ特定できる Ex. 選挙人名簿、住民票 参与観察 participant observation定性的社会調査法の1つ - 野外調査中心数ヶ月-数年に渡り研究対象社会に滞在しメンバー一員とし生活 外部に閉ざされた様な特異集団調査に威力発揮 (定型的方法未確立) Ex. ウィリアム・フット・ホワイト「ストリート・コーナー・ソサエティ」
社会学・人類学で、特定社会集団研究に用いる + 家庭、教室、会社組織等に対しても用いる 特徴問題発見しやすく、問題特質を浮き彫りにさせやすい対象の多次元的な把握に向き全体像描きやすい 問題事象対象者の経験をその内面に遡り理解し、対象者の行為を意味付け問題の深層にアプローチできる 時間を遡り調べられるので対象の変化の過程をとらえられる 欠点事例極めて少 - 標本としての代表性が問題定型的方法未確立 → 分析成否が研究者・調査者の能力や性格に依拠
一般化困難で主観混じる不的確な観察や恣意的推論の介入する余地大 |
|
調査成否は計画立案段階にある: 明確な課題・問題意識 - 解を得る調査実施 = 仮説検証: 最初にアンケート計画 → 計画に従い実施(must)
計画不十分アンケート → 信頼できる結論・行動指針は何も得られない Ex. 仮説検証できない質問 「どのような新薬が売れると思いますか」 ⇒ 『バカ丸出し質問』と『信ずるものは救われる型分析』 現状把握: 研究テーマ等、関心事に関する現状調査し問題状況把握(推定)し、意思決定や仮説設定等の次行動に活用→ 調査対象や回収データの解析方法等は、目的により自然と決まる アンケート調査計画立案内容10項目: 2との関わりで7を事前決定することが質問項目設定に直接関わり調査表作成に際し重要
1. 目的: 結果を何のために使う
6. 方法: どのように調査 後日、情報としても活用しやすいため、報告書とし文書で行うのがよい アンケート計画決定 → 準備Ex. 調査票作成 → 予備調査(+ パイロット調査) → 調査票修正 → 実施準備(調査員・会場等) → 本調査 → 集計 → 分析(解析) → 評価 調査票作成= 質問文 + 回答文 = データ質・内容左右 → 細心の注意と十分な検討必要
調査票に調査目的項目全て含める必要 ≠ 項目を全て並べる
質問文作成: 調査者-回答者間の正確・円滑なコミュニケーションには、質問の意味が正しく理解できるよう、簡潔で明瞭かつ具体的質問文の用意必須
ワーディング: 言葉の言い回し- 回答に大きく影響
パイロット調査: 本調査前に小規模調査を実行し調査全体を検討 アンケート調査回答方法類別回答の性質により統計処理の方法異なる固定選択式(選択回答法): 予想される回答内容予め用意 - 該当を選択回答 単数回答 (single answer, SA) Ex. あなたの血液型を教えてください 1) A 2) B 3) AB 4) O 5) 不明 複数回答(multiple answer, MA)Ex. 次の家電製品中からお宅でご使用のものを全て選んで下さい 1) 洗濯機 2) 掃除機 3) エアコン 4) 冷蔵庫 5) 炊飯器 6) レンジ 人の意見や感覚をデータとして集める方法として広範に利用事前に質問文用意: 答え方を通じ回答者の意見・感覚知るデータ収集方法
元々「郵便質問紙による調査」の意味 → 郵送以外の方法も含める 記述回答式: 目的によるが、統計資料への調査結果利用考えると統計処理できない記述回答避ける
数量回答: 数字記入を求める 文字回答(オープンエンド): 文字通り質問に自由に回答してもらう ☛ 標本誤差 (≈ 統計的誤差): 誤差計算できない調査は信用できない非標本誤差 (≈ 非統計的誤差): 標本抽出の偶然性とは関係なく生じる誤差
= 抽出方法・標本サイズ変えても減らせない誤差 → 客観的評価困難
2, 3は調査方法に大きく依存 Def. 実査 field interviewing: 対象者への訪問面接による一連の情報収集
インストラクション: 調査員に実施要領の説明を行う会 - 「手引き」有効
↓ 調査員が調査票を持ち、調査対象者の自宅/勤務先訪問 集団面接法 group interview or group discussion パネル調査法 panel survey = 時系列調査 インターネットアンケート 深層面接法 depth interview = 精神分析的面接法 psycho-analytic interview 投影法 projective technique 詳細面接法 detailed interview 偽装実験法 SP (subliminal perception) Def. 回収 recovery: 調査の完了した調査票を受け取ること
エディティング editing: 回収済調査票の空欄や矛盾回答等を点検 = "一部でも記入"ある回収質問表/全配布数 低回収率: 非標本誤差大 → 統計的推測成立困難 → 標本 ≠ 母集団縮図
⇒ 歪み = 回収率・回答偏りに注意し調査方法選択 メーキング(インチキ、チーター): (アルバイト調査員による)データ捏造
全票メーキング: 断固として排除せねばならない ∴ 調査員の質は重要
準備: モラル教育 + 信頼関係 + 十分な報酬
回収数 ∝-1 回答誤差 ⇔ 回収率:∝-1 回答偏り
→ 質問項目によっては有効回答率が見かけの回収率より更に低くなる Def. 無回答誤差 nonresponse error: 回答しなかった人が回答した人と体系的に異なるため調査結果が母集団の実態からずれる誤差 Ex. 1質問項目のyes-no回答求める調査
無回答(無回答群)中には本音がyesあるいはnoが含まれる
- これが知りたい
∴ Ty = (Ar·Ta + Rr·Rn)/Tn Ty = Ar·Fa + Rr·(1 - Fa) // ⇒ Ty = Ar + (1 - Fa)(Rr - Ar)Def. 最大偏差幅: 無回答誤差の大きさ(回答者-非回答者の差), Ae
≡ |Rr – Ar| ∴ Ar − Ae < Ty < Ar + Ae … (1)
(1)より 0.6 - 0.2 < Ty < 0.6 + 0.2 ∴ 0.4 < Ty < 0.8 (よくない)
回答率低いと誤差急増 Rr − Arが大きいと誤差急増 母集団特性知る = データは科学的に裏付けられた方法で処理する 場所・時期: データ偏りに関与
Ex. 季節商品調査: 時期で結果異なる → 年次変化見るには時期統一 Def. 妥当性 validity: 測定が本来測るべき概念を正しく捉えている程度
信頼性・妥当性がアンケート精度(信頼性)を判断するポイント
ある集団構成員に対する調査 → 集団特性・傾向知る
集団の特色や傾向を把握する最初の手続 Ex. 1 日 2 ウィ 3 ビ 4 ワ 5 カク
質問に20人中10人が○を付けた。○を付けない人はアルコール飲料を飲まない人や選択肢の種類に好みがなかい人等含む。この無回答誤差は、質問をアルコール飲料を飲む人だけが答えるよう設問を組立て、選択肢中に"その他"を設け、小さくできる。選択回答法アンケート調査は、回答者が必ず選べる選択肢用意すると調査精度高まる コーディング coding: 各カテゴリーに対応するコード(符号)を与えること
※ DK (don't know) ≠ 無回答 |
Q. 会食時に好んで飲むアルコール類を教えて下さい(複数回答可)
1 日本酒、2 ウィスキ、3 ビール、4 ワイン(含シャンパン)、5 カクテル クロス集計 cross tabulation: 質問項目間関連を調べる最初の手続 2質問項目回答を表の縦横にクロス集計 - 調査データはカテゴリー・数量の2種類 → 組合わせたクロス集計は3種類 → 集計タイプに応じ統計手法決まる
分割表: クロス集計表がカテゴリーデータ含むのを明示する呼称
1) カテゴリー/カテゴリー → クラメールの独立係数 Case. 複数回答: 回答比率を表す母数の選び方で回答者数比率と回答数比率があり、独立係数算出法異なる Ex. 年代と酒の好みとの関連調べる → 晩酌するという10人の人に次の質問 2種類以上の酒類を飲む人で組合わせに偏りがあるかを調べる 問1 晩酌でよく飲むお酒類の種類を全て教えて下さい(○はいくつでも)
1. 日本酒 2. ウィスキ 3. ビール 4. その他
1. 29歳以下 2. 30-49歳 3. 50歳以上
表. 回答一覧 (番号 = 回答者番号) a) 回答者数比率のクロス表 Ex. 年代と酒の好みの関連を調べる 表. 年代と酒類のクロス表。()内は比率 年齢 回答者数 日本酒 ウィスキ ビール その他 合計
酒類横計と回答者数の縦計が一致せず、単1回答のように直接に独立係数算出はできない 酒種類ごとに飲む人飲まない人を年代でブレイクダウンしクロス表作成 単1回答同様手続で酒毎のχ2求め、各々の独立係数を得て相関評価 表. クロス表 (T 回答数. Y/N 飲む/飲まない, N = T – Y)。( )期待度数日本酒 ウィスキ ビール その他 T Y N Y N Y N Y N 全体(総計) 10 7 3 3 7 6 4 4 6 29歳以下 3 1(2.1) 2(0.9) 1(0.9) 2(2.1) 2(1.8) 1(1.2) 2(1.2) 1(1.8) 30-49歳 3 2(2.1) 1(0.9) 2(0.9) 1(2.1) 3(1.8) 0(1.2) 0(1.2) 3(1.8) 50歳以上 4 4(2.8) 0(1.2) 0(1.2) 4(2.8) 1(2.4) 3(1.6) 2(1.6) 2(2.4)
表. 酒類連関クロス表
表. 各酒のχ2値と独立係数 (rc) (対角線上値 = 全体行値) A B C D 全体 酒類 日本酒 ウィスキ ビール 他 χ2 3.65 3.65 4.10 3.19 rc 0.60 0.60 0.64 0.57
全rcが0.8 > rc > 0.5 → 年代-酒類 = "やや強い相関" ☛ 2種類以上飲む時に組合わせの多い酒類見つける → 表側項目と表頭項目共に酒種類 → クロス表作成 各酒組合わせで「飲む」「飲まない」クロス表作り、それぞれの独立係数求めるStep 1) 日本酒/ウィスキ → 「全体」行から、日本酒、ウィスキそれぞれを飲む人数をセルに記入
Step 1 ウィスキ Step 2 Step 3 ウィスキ Step 3) 回答者数の行と列を除くと、「飲む」「飲まない」だけのクロス表になる イェーツの連続修正(イェーツの補正) Yates' continuity correction
データ数 < 5 → χ2計算時行う補正
表. 酒類各組合せχ2値と独立係数
[結論] 対象集団10人について
各セルの比率が回答総数に対する比率で表せ、独立係数は、単1回答と同様に考え算出できる
表. 年代と酒類のクロス表。()内期待度数
酒類 日本酒 ウィスキ ビール その他 酒類(横形)
表. 期待度数からのずれの度合
カテゴリー数は、年代別が酒類より小さいので、n = 20、k = 3を式に代入すると、独立係数rc = 0.394 カテゴリーデータ(数量データ)の取り扱いEx. 香水3銘柄A、B、C に、「ご自身が使用するとすればどれを選びますか」という質問項目を用い、ある女性集団20名に対し行ったアンケート結果
表. 香水と選んだ女性の年齢
香水銘柄により平均年齢差あり、香水に年齢による嗜好偏りがある。平均値同じでも「無相関」と判断できない → Ex. 30代集中銘柄と20代、40代に同数の嗜好者が集中する銘柄では、両者の平均値同じ 級間変動(グループ間変動) between-groups sum of squares, sb: カテゴリー間平均値の違いを示す指標
Sb = Σi=1nni·(xi – x)2, ni, 各級標本数。xi:: 各級平均値。x: 全体平均 → 大きさ: 各級の数量データと級の平均値との差の平方和をカテゴリーデータ全体についての総和 結論: 年齢幅小 → 銘柄-年齢関係強。各銘柄平均値が全体平均値より離れる → 銘柄と年齢の関係強表. 平均値との差の平方和(偏差平方和)の計算 A年齢 差の2乗 B年齢 差の2乗 C年齢 差の2乗 26 (26-27)2 = 1 35 (36-34.5)2 = 0.3 46 (46-34.9)2 = 123.2 33 (33-27)2 = 36 30 (30-34.5)2 = 44.9 41 (41-34.9)2 = 42.3 25 (25-27)2 = 4 40 (40-34.5)2 = 10.9 40 (40-34.9)2 = 30.3 23 (23-27)2 = 16 43 (43-34.5)2 = 39.7 27 (27-34.9)2 = 56.3 28 (28-27)2 = 1 38 (38-34.5)2 = 1.7 26 (26-34.9)2 = 72.3 36 (36-34.5)2 = 0.5 22 (22-34.9)2 = 156.3 33 (33-34.5)2 = 13.7 39 (39-34.9)2 = 20.3 合計 S1 = 58 S2 = 111.4 S3 = 510.4 級内変動, Sw = S1 + S2 + S3 = 58 + 111.4 + 510.4 = 679.8 相関比(寄与率) correlation ratio, η2 = Sb/(Sb + Sw) → Sb = 0 → η2 = 0 (Min.), Sw = 0 → η2 = 1 (Max.)
級内変動小/級間変動大 → 相関強い
η2 > 0.8 0.8-0.5 0.5-0.25 0.25 > 影響の有無の数値的扱い方Ex. 健康影響評価: 2値データ比較(四分表)比と差による比較(主に比) → 多カテゴリの検討、数量による検討
比較のための分割表(四分表, 2 × 2分割表、クロス表) リスク比 (risk ratio), φ = (a/n1)/(c/n0) = an0/cn1 (発生)率比 incidence rate ratio, rate ratio, R^R = (a/P1)/(c/P0) = aP0/cP1 オッズ比 odds ratio, φ^ = (a/c)/(b/d) = ad/bc ≈ φ
標本値 → 母集団推定(一般化)で、値の精度が問題(誤差) = 信頼区間 影響ありと判断する基準 コジョイント分析 conjoint analysisEx. アンケート調査: 商品選好 → 好きな順番(順序変量)尋ねると答え易い個々要因効果と同時結合尺度 conjoint scale 同時推定 (Ex. 好む商品と、その選好要因) 表1 コンジョイント分析の発展プロセス (Louviere 1990)モデル - 被験者の選好測定 - パラメータ推定
事後調査(吟味調査): 解釈・評価の結果必要な場合実施 |
目的評価 by (Ex. ジョブインタビュー: 情報収集 - インタビュー者口調・トーン重要)形式構造化インタビュー: 統計的集計, 短時間一問一答式の質問票(アンケート)調査に近い 半構造化インタビュー: 統計的集計・質的調査, 中時間事前に大まかな質問事項を決め、回答者の答により詳細にたずねて行く簡易な質的調査法。長時間インタビュー行えない時などに効果的 非構造化インタビュー
質問内容を特に定めず、回答者が無意識な部分を引き出すのが目的 |
デプス(深層)インタビュー: 質的調査, 長時間 現場で実際に対象物を使用してもらいながら行う グループインタビューグループインタビュー: 統計的集計, 中時間 グループに対し質問票に記入してもらいつつ、会話から得る意見も収集 → 個人より集団としての消費者行動などの把握に適 フォーカスグループインタビュー: 質的調査, 長時間 1課題でグループ討論 → 安心感や連鎖反応起こりやすく、インタビュアーから直接質問されないため自発的コメント取りやすい |

 図. 信号のアナログ解釈とデジタル解釈
図. 信号のアナログ解釈とデジタル解釈
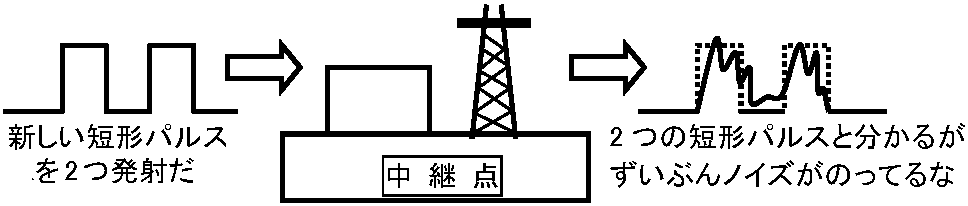 図. パルス中継
図. パルス中継
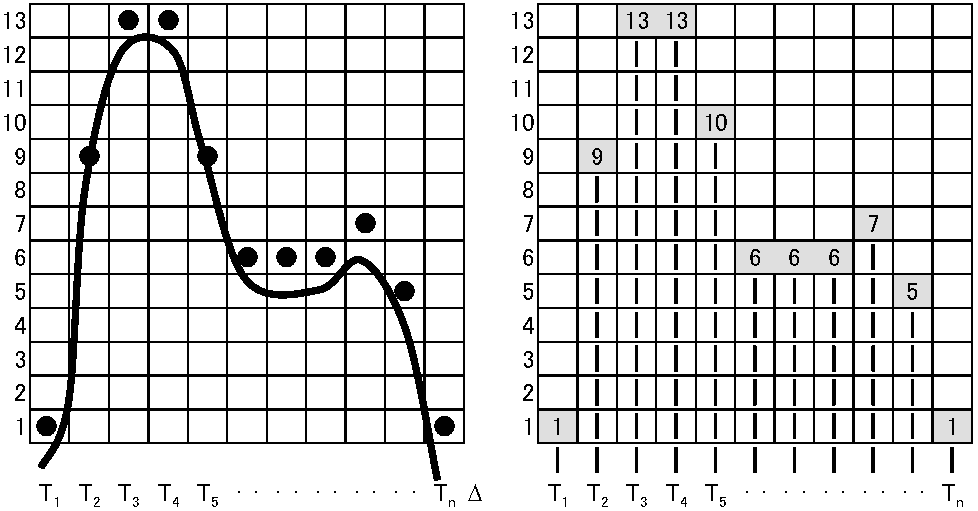 標本化
標本化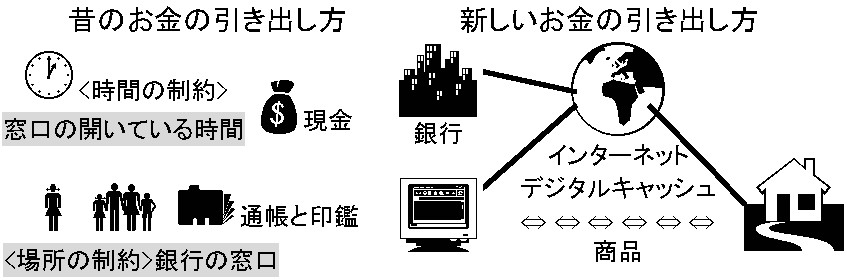
{kind=link}